[Paper Reivew] AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
본 논문에서는 AnomalyDiffusion이라는 few-shot diffusion 기반 anomaly generation 모델을 제안합니다.

AAAI 2024, [Paper] [Github] [Page]
Teng Hu, Jiangning Zhang, Ran Yi, Yuzhen Du, Xu Chen, Liang Liu, Yabiao Wang, Chengjie Wang
Shanghai Jiao Tong University, Youtu Lab, Tencent
22 Feb 2024
Abstract
Anomaly inspection은 산업 제조에서 중요한 역할을 합니다. 기존 anomaly inspection 방법은 불충분한 anomaly data로 인해 성능에 한계가 있습니다. anomaly data를 증강하기 위해 anomaly generation 방법이 제안되었지만, 이들은 생성된 anomaly의 authenticity가 떨어지거나 generated anomalies와 masks 사이의 alignment가 정확하지 않다는 문제를 가지고 있습니다.
이러한 문제를 해결하기 위해, 우리는 새로운 diffusion 기반 few-shot anomaly generation 모델인 AnomalyDiffusion을 제안합니다. 이 모델은 대규모 dataset으로 학습된 Latent Diffusion Model (LDM) 의 strong prior 정보를 활용하여, few-shot training data에서도 generation authenticity를 향상 시킵니다.
먼저, 우리는 학습 가능한 anomaly embedding과 anomaly mask에서 인코딩된 spatial embedding으로 구성된 Spatial Anomaly Embedding을 제안하여, anomaly 정보를 anomaly appearance와 location 정보로 분리합니다.
또한, generated anomalies와 anomaly masks 사이의 alignment를 개선하기 위해, 우리는 새로운 Adaptive Attention Re-weighting Mechanism을 도입합니다. 이 메커니즘은 generated anomaly image와 normal sample 간의 차이에 따라 모델이 덜 noticeable한 generated anomaly 영역에 더 집중하도록 동적으로 안내하여, 정확하게 일치하는 anomaly image-mask pairs를 생성할 수 있게 합니다.
Extensive experiments를 통해, 우리 모델은 generation authenticity와 diversity 면에서 state-of-the-art 방법을 크게 능가하며, downstream anomaly inspection tasks의 성능을 효과적으로 향상 시킴을 입증합니다.
TL;DR:
본 논문에서는 AnomalyDiffusion이라는 few-shot diffusion 기반 anomaly generation 모델을 제안합니다.
- Spatial Anomaly Embedding 방법으로 anomaly location과 appearance 정보를 분리하고,
- Adaptive Attention Re-weighting Mechanism을 활용하여 anomaly generation의 alignment와 authenticity를 향상 시켰습니다.
1. Introduction
산업 제조에서 anomaly detection(AD), localization(AL), classification(AC)은 중요한 역할을 합니다. 하지만 실제 환경에서는 anomaly 데이터가 매우 적기 때문에 이 작업들이 어려워집니다. 대부분의 기존 방법들은 normal sample을 중심으로 학습하는 unsupervised learning이나, 소수의 anomaly 데이터만으로 학습하는 few-shot supervised learning에 의존하고 있지만 이러한 방식들은 anomaly localization과 anomaly classification에서 성능이 제한적입니다.
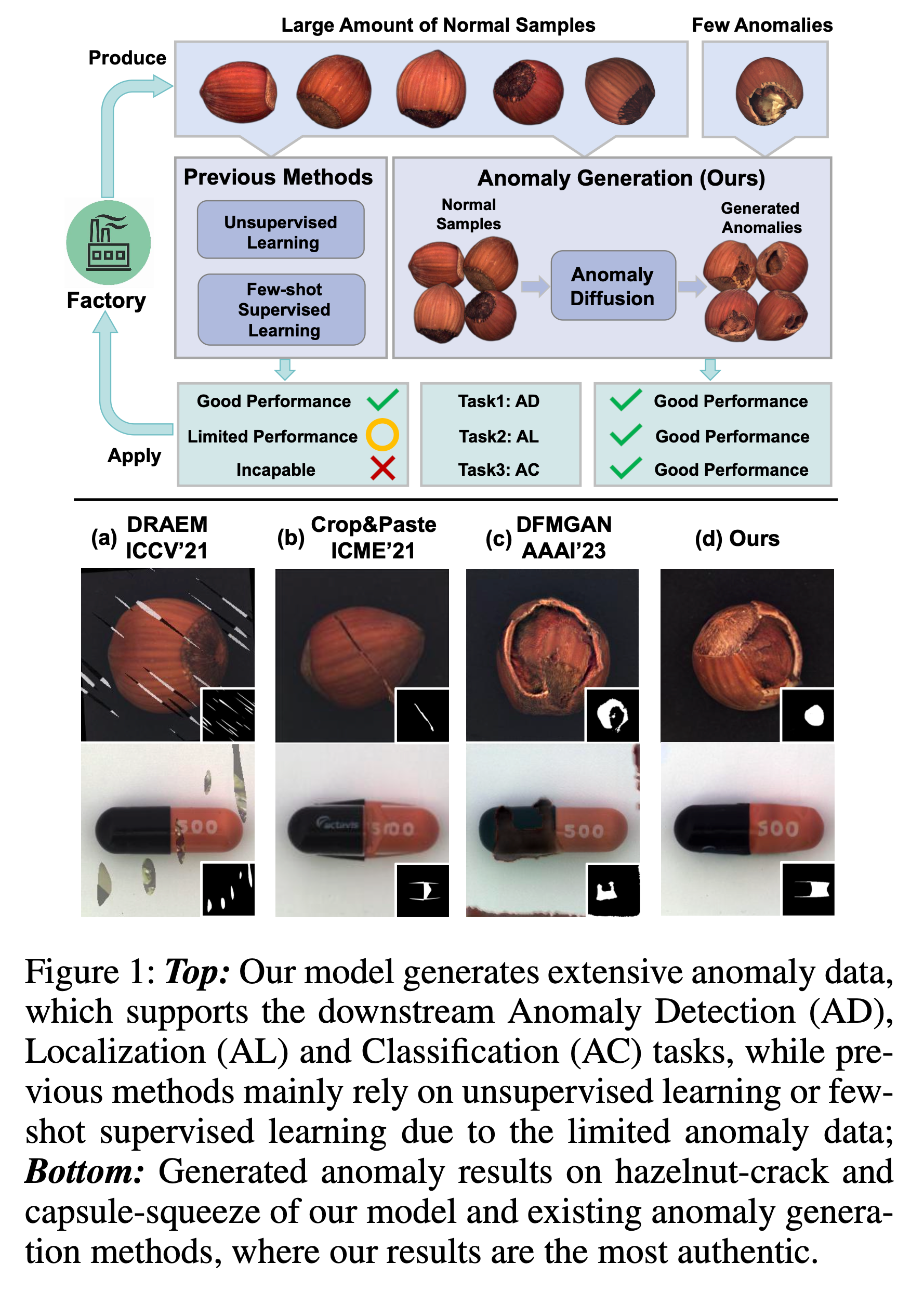
이 문제를 해결하기 위해 anomaly generation 방법들이 제안되었지만, 이들 방법은 크게 두 가지가 있다고 합니다.
- 진위성(authenticity): 기존 모델들은 생성된 anomaly가 실제 anomaly처럼 보이지 않는 경우가 많습니다. 예를 들어, crop and paste 방식은 그냥 anomaly 부분을 잘라서 다른 이미지에 붙이기 때문에 실제 anomaly와는 거리가 있습니다.
- 정합성(alignment): anomaly와 anomaly mask가 정확히 일치하지 않는 문제도 있습니다. 이는 anomaly generation을 anomaly detection, localization, classification 같은 downstream task에서 제대로 활용하기 어렵게 만듭니다.
본 논문에서는 이러한 한계들을 해결하기 위해, AnomalyDiffusion이라는 새로운 모델을 제안합니다. 이 모델은 두 가지 핵심 기술을 사용합니다:
- Spatial Anomaly Embedding: anomaly 정보를 anomaly의 appearance와 location 정보로 분리하여, 원하는 위치에 정확한 anomaly를 생성할 수 있게 합니다.
- Adaptive Attention Re-weighting Mechanism: anomaly와 normal sample 간의 차이를 기반으로 덜 눈에 띄는 anomaly 영역에 더 집중하도록 모델을 안내해, anomaly와 anomaly mask의 alignment를 향상 시킵니다.
이 모델은 대규모 데이터셋에서 학습된 Latent Diffusion Model (LDM) 의 사전 지식을 활용해, 적은 anomaly 데이터로도 높은 authenticity와 diversity를 보장합니다.
요약하자면…
- 기존 anomaly generation 방법들의 한계: 많은 기존 방법들이 few-shot 문제에서 생생한 anomaly 생성에 실패하거나, anomaly와 mask 간의 alignment 문제를 해결하지 못함
- 두 가지 핵심 방법: Spatial Anomaly Embedding과 Adaptive Attention Re-weighting Mechanism으로 anomaly generation를 개선!
- Anomaly generation으로 생성된 이미지는 Downstream task에 도움이 되더라~
2. Related Work
2.1. Generative Models
Generative Models
- VAE와 GAN에 비해, Diffusion Model이 authenticity와 diversity 면에서 더 높은 잠재력을 보입니다.
- 특히 Latent Diffusion Model (LDM) 은 확산 모델의 학습 공간을 압축하여 효율성을 높이고, 대규모 데이터셋에서 강력한 prior를 학습함으로써 few-shot 상황에서 유리합니다.
Few-shot Image Generation
- Few-shot 이미지 생성 연구들은 주로 네트워크 가중치를 수정하거나 다양한 정규화 기법 및 데이터 증강을 통해 과적합을 방지하려고 시도해 왔습니다.
- 최근에는 cross-domain consistency loss를 도입하거나 Textual Inversion, Dreambooth와 같은 방법을 사용하여 few-shot 이미지를 생성하는 시도가 있었으나, 이들 방법은 anomaly 위치를 정확하게 제어하는 데 어려움이 있었다고 합니다.
2.2. Anomaly Inspection
Inspection
- Anomaly inspection은 anomaly Detection(AD), Localization(AL), Classification(AC)로 나뉩니다.
- 기존 일부 방식은 reconstruction 기반으로 anomaly를 탐지하고 localization을 시도했지만, anomaly의 정확한 위치를 찾는 데에는 한계가 있었습니다.
- Deep feature modeling 기반의 방법들은 이미지의 feature space를 학습하여 정상 이미지와 anomaly 간 차이를 분석하려 했으나, 데이터 부족 문제는 여전히 큰 도전 과제로 남아 있습니다.
Generation
데이터 부족 문제를 해결하기 위해 anomaly generation이 제안되었지만, 두 가지 주요 문제를 가지고 있었습니다:
- Authenticity : 생성된 anomaly가 실제 anomaly처럼 보이지 않는 경우가 많다고 합니다. 예를 들어, Crop and Paste 방법은 단순히 anomaly 부분을 잘라내 다른 이미지에 붙이는 방식입니다.
- Alignment: anomaly와 anomaly mask가 정확히 일치하지 않아 downstream task(AD, AL)에서 성능을 저하시켰습니다.
GAN 기반 모델들도 few-shot 상황에서 충분한 anomaly data를 생성하는 데 어려움을 겪었으며, DFMGAN이 일부 개선을 시도했으나, 여전히 alignment 문제가 남아 있었습니다.
3. Method
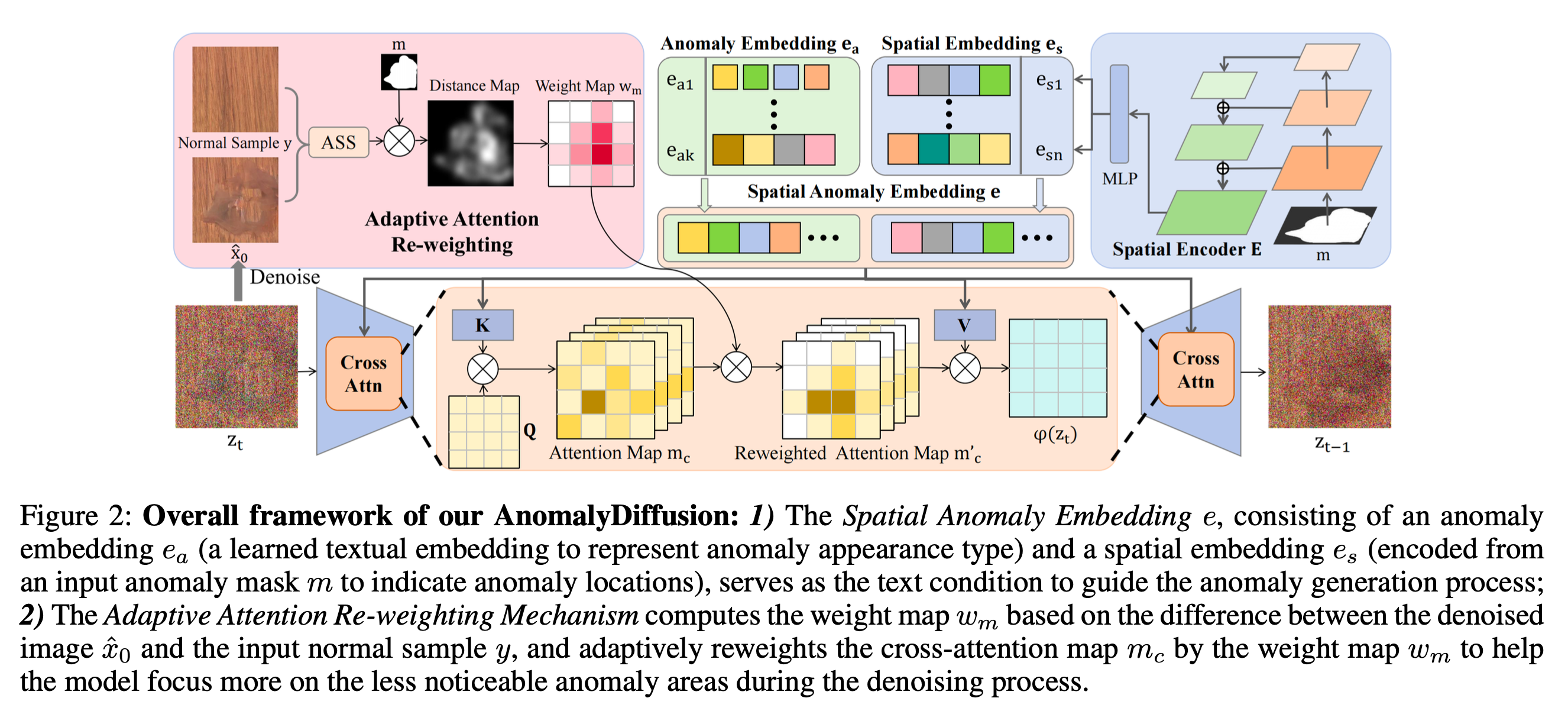
AnomalyDiffusion은 few-shot anomaly generation을 목표로 하는 diffusion 기반(Latent Diffusion Model, LDM1 ) 모델입니다.
- Input: anomaly가 없는 sample y와 anomaly mask m
- Output: anomaly가 mask 영역에 생성된 anomaly 이미지
AnomalyDiffusion 모델에서 특이한 점은, 위치 정보와 anomaly 외관 정보를 나누어 다룬다는 점입니다.
- \(e_a\): anomaly의 외관(appearance) 정보를 제공하는 Anomaly Embedding
- \(e_s\): anomaly의 위치(location) 정보를 제공하는 Spatial Embedding
이 두 embedding을 concat하여, anomaly의 외관과 위치 정보를 모두 포함하는 Spatial Anomaly Embedding e을 얻고, diffusion 모델에서 text condition과 비슷하게 guidance로서 작용합니다.
이후 Blended Diffusion2과 비슷하게 foreground와 background를 mask로 나누어 이미지를 생성합니다.
\[x_{t-1} = p_\theta(x_{t-1} \mid x_t, e) \odot m + q(y_{t-1} \mid y_0) \odot (1 - m)\]- \(x_t\): timestep \(t\)에서의 생성된 anomaly 이미지
- \(y_0\): 입력 normal sample
- \(m\): anomaly mask
- \(p_\theta(·) , q(·)\): forward/backward process
이 수식은 diffusion 과정에서 anomaly가 mask 영역에만 생성되고, 나머지 영역은 정상적으로 유지하려는 아이디어로부터 나왔습니다.
3.2. Spatial Anomaly Embedding
구체적으로 embedding을 만드는 방법에 대한 소개입니다.
Disentangle Spatial Information from Anomaly Appearance
Spatial Anomaly embedding의 주요 목표는 anomaly의 Anomaly appearance(외관)와 Spatial(위치) 정보를 분리하는 것입니다. 기존의 anomaly generation 방법들은 이러한 정보를 한꺼번에 처리하여 정교한 제어가 어려웠지만, AnomalyDiffusion은 두 정보를 분리하여 더욱 효과적으로 anomaly를 생성합니다. anomaly가 생성되는 위치를 정확히 제어할 수 있으며, anomaly의 형태 또한 다양하게 생성할 수 있습니다.
Anomaly Embedding
Anomaly의 외관 타입 정보를 학습한 textual embedding을 Anomaly embedding, (\(e_a\)) 이라고 합니다. 일반적인 Diffusion model과는 다르게 저자들은 masking을 이용해 불필요한 배경 이미지를 가림으로써, anomaly 영역만을 모델이 볼 수 있게 제한합니다. 이 방식을 masked textual inversion라고 하며 다음 식으로 학습할 수 있습니다.
\[\mathcal{L}_{dif} = \| m \odot (\epsilon - \epsilon_\theta (z, t, \{ e_a, e_s \})) \|_2^2\]Spatial Embedding
정확한 위치 정보를 제공하기 위해 저자들은 Spatial embedding, (\(e_s\)) 를 사용합니다. Spatial Encdoer \(E\)는 anomaly mask, \(m\)을 \(e_s\)로 인코딩합니다.
\[e_s = E(m_i)\]저자들은 ResNet-50 모델을 이용해 image feature를 다양한 layer에서 뽑아내고 Pyramid 형태로 fuse하여 embedding을 얻었다고 합니다.
Overall Training Framework
- 입력으로 image-mask pair \((x_i, m_i)\)를 받습니다.
- Encoder \(E\)에 인풋 마스크 \(m_i\)를 태워, \(e_s = E(m_i)\) 를 얻습니다.
- \(i\)-th anomaly type에 대한 embedding, \(e_{a, i}\) 를 \(e_s\) 와 concat합니다. \(e = \{e_a, e_s\}\)
- \(e\)를 text condition처럼 diffusion model에 태워 diffusion model을 학습시킵니다.
정리하자면…
Spatial 과 Anomaly appearance를 한번에 embedding하지 말고, 따로 임베딩하자!
Spatial embedding + Anomaly embedding = Spatial Anomaly embedding
이렇게 얻은 embedding을 LDM에서 conditioning에 사용!
3.3. Adaptive Attention Re-Weighting
Spatial Anomaly embedding을 이용해 이미지를 생성하는 경우, 특히 불규칙한 마스크를 사용하는 경우 전체 마스크를 채우는데 어려움이 있었다고 합니다. 이를 해결하기 위해 저자들은 Adaptive Attention Re-Weighting 방법을 제안합니다.

Adaptive Attention Weight Map
- t번째 denoising step에서, 먼저 \(\hat{x}_0 = D(p_\theta(\hat{z_0} \vert z_t, e))\)을 예측하고, 정상 이미지 y와 anomaly mask m의 pixel-level 차이를 계산합니다.
- 이 차이를 이용해 Adaptive Scaling Softmax를 수행합니다.
여기서 \(f(x) = \frac{1}{x}\) 이고, 이는 mask 영역 내에서 anomaly가 눈에 잘 띄지 않는 부분에 대해 더 높은 가중치를 할당하는 역할을 합니다.
Attention Re-weighting
계산된 weight map \(w_m\)을 사용해 cross-attention 계산을 제어합니다. 이는 모델이 생성된 anomaly가 less noticeable 영역에 더 많은 attention을 할 수 있도록 합니다.
Query는 latent code \(z_t\)로부터, key, value는 spatial anomaly embedding \(e\)로부터 생성됩니다.
\[Q = W_Q^{(i)} \cdot \phi_i(z_t), \quad K = W_K^{(i)} \cdot e, \quad V = W_V^{(i)} \cdot e\]이때 \(\phi_i(z_t)\)는 U-Net의 intermediate representation
저자들의 Attention Re-weighting 방법은 다음과 같이 표현할 수 있습니다.
\[\text{RW-Attn}(Q, K, V) = m'_c \cdot V, \quad \text{where } m'_c = m_c \odot \textcolor{blue}{w_m} = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \odot w_m\]불규칙한 마스크 영역에서 anomaly가 다 채워지지 않는 문제가 있었음.
이를 해결하기 위해 attention re-weighting 방법 사용!
Cross-attention attention map에서 weight , \(\textcolor{blue}{w_m}\)를 곱해주어 less noticeable 영역에 attention 높이기
3.4. Mask Generation
AnomalyDiffusion 모델은 anomaly mask를 입력으로 받아 anomaly 이미지를 생성합니다. 그러나, dataset에서 anomaly mask의 수가 매우 적기 때문에, mask 생성을 위한 Mask Generation 메커니즘을 도입했다고 합니다.
- Textual Inversion을 사용해 anomaly mask의 분포를 학습하고, 이를 통해 **mask embedding ** \(e_m\)을 생성합니다.
- Mask embedding을 text-condition처럼 사용해 mask를 생성할 수 있었다고 합니다.
4. Experiments
4.1 Experiment Settings:
Dataset:
- 실험은 MVTec AD (Bergmann et al., 2019) 데이터셋에서 수행되었습니다. 이 데이터셋은 anomaly detection 및 localization에 널리 사용되는 데이터셋으로, 다양한 산업용 물체와 텍스처에서 발생하는 anomaly를 포함합니다.
- 전체 anomaly 데이터의 3분의 1은 training , 나머지 3분의 2는 test
Implementation Details:
- Anomaly Embedding에 대해 \(k = 8\)개의 토큰, Spatial Embedding에 대해 \(n = 4\)개 의 토큰, Mask Embedding에 대해 \(k' = 4\)개의 토큰을 할당합니다.
- 각 anomaly 유형에 대해 1000개의 이미지-mask 쌍을 생성하여 downstream anomaly inspection 작업에 사용합니다.
Metric:
- Inception Score (IS): 생성된 이미지의 품질과 다양성을 평가하는 지표. 높은 값일수록 더 나은 품질과 다양성
- Intra-cluster pairwise LPIPS distance (IC-LPIPS): 생성된 이미지의 다양성을 측정하는 지표. 높을수록 더 다양한 이미지를 생성한 것
- AUROC, Average Precision (AP), F1-max: anomaly detection 및 localization의 정확성을 평가
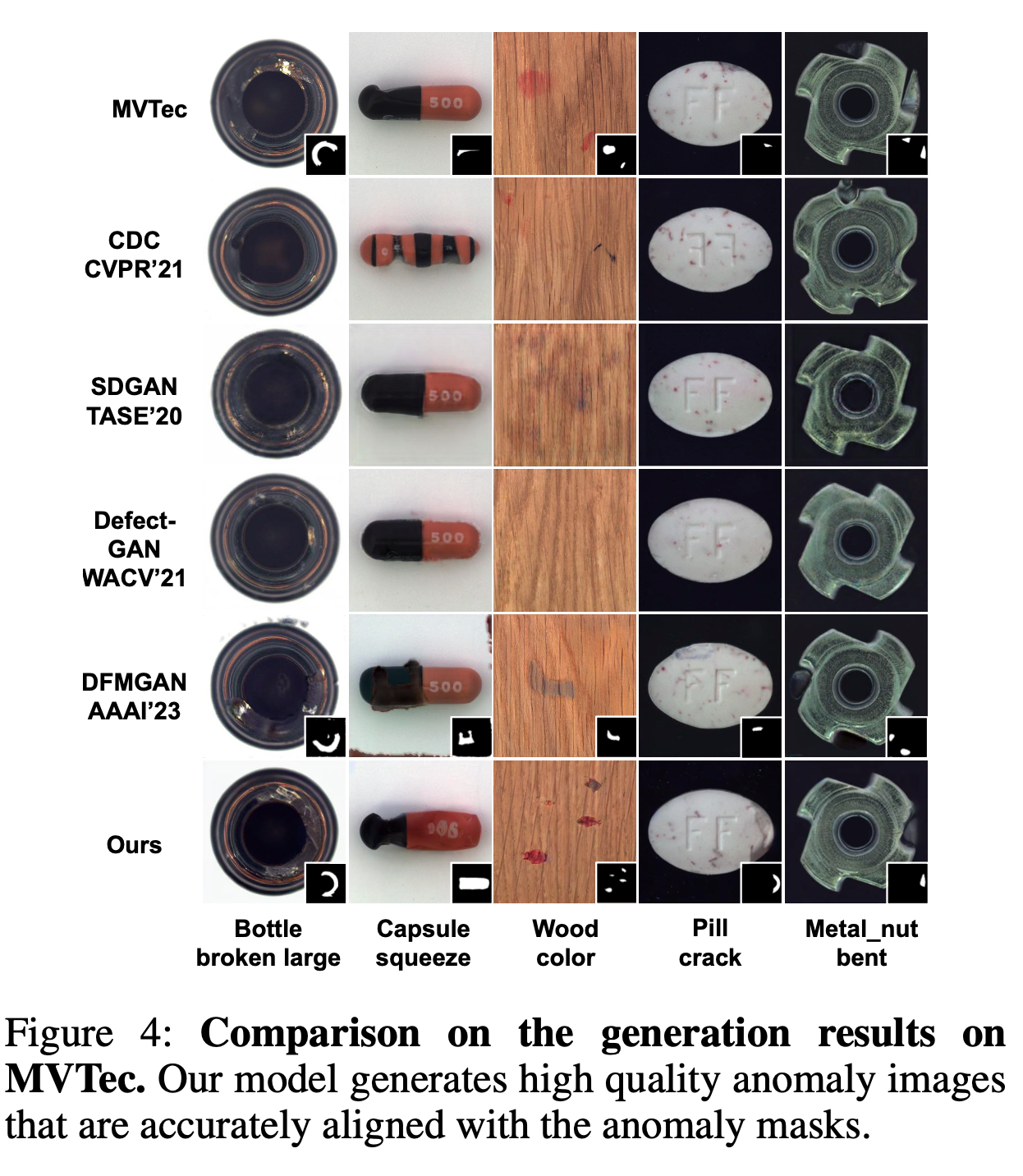
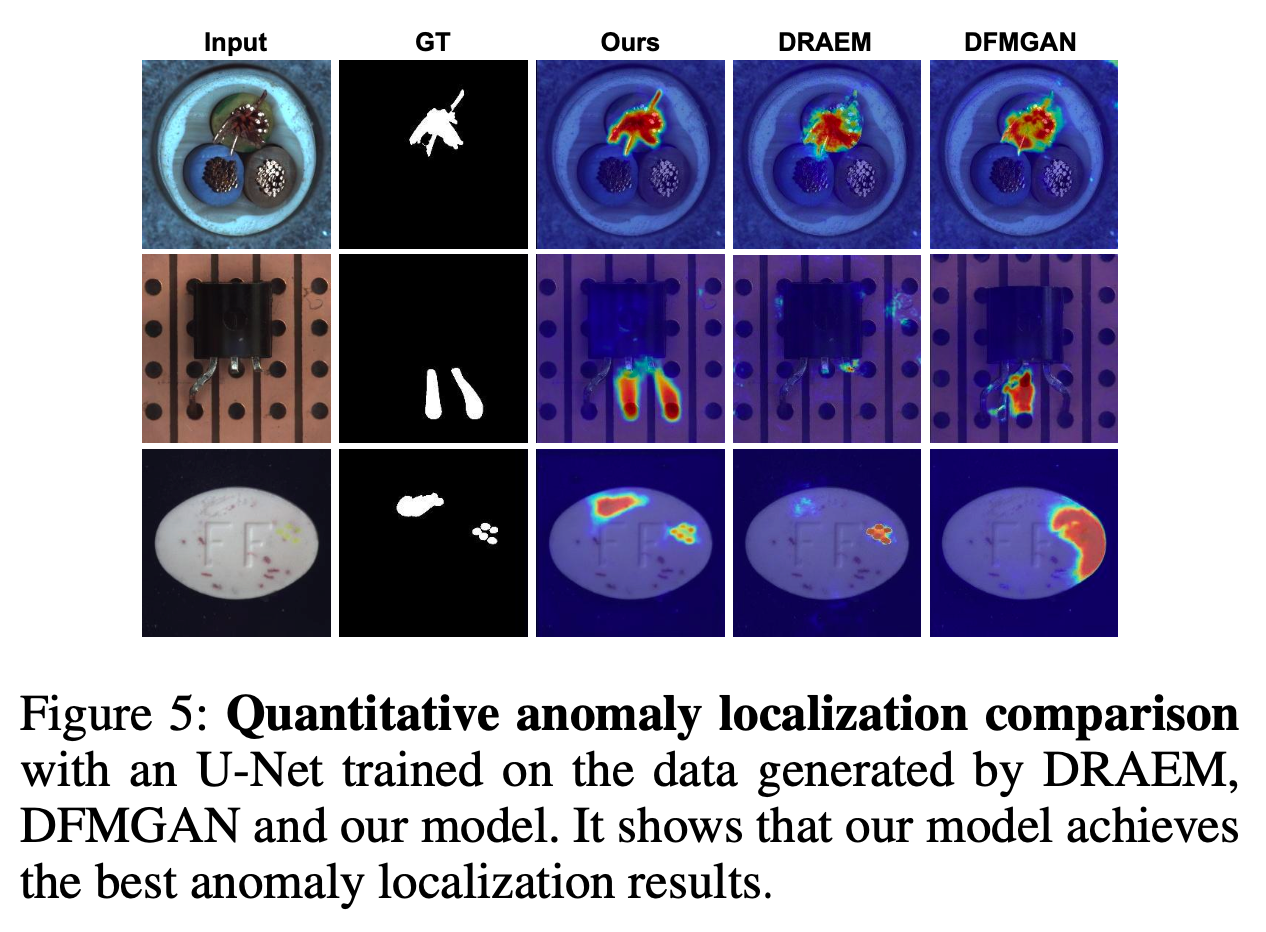
5. Conclusion
논문에서는 AnomalyDiffusion이라는 새로운 anomaly generation 모델을 제안했습니다. 이 모델은 anomaly의 appearance(외관)와 location(위치) 정보를 분리한 후 anomaly embedding과 spatial embedding으로 표현합니다. 또한 adaptive attention re-weighting mechanism을 도입해, mask와 anomaly의 alignment를 향상시켰습니다.