[Paper Reivew] AnyText: Multilingual Visual Text Generation and Editing
Diffusion-based multilingual visual text generation and editing model AnyText 제안.

ICLR 2024 (Spotlight) [Paper] [Github]
Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, Xuansong Xie
Alibaba Group
21 Feb, 2024
TL;DR
Diffusion-based multilingual visual text generation and editing model AnyText 제안. Auxiliary Latent Module, Text Embedding Module을 이용해 text rendering 정확도 높임.

1. Introduction
대부분의 Diffusion model들은 잘 형성되고 읽을 수 있는 visual text 생성에 어려움을 겪습니다. 저자들이 생각하는 이 문제의 원인은 다음과 같습니다.
- Large scale image-text pair dataset이 없음. Large scale dataset이라하면 보통 LAION-5B을 사용하는데, 이는 text content를 위한 OCR 결과등이 부족하다고 합니다.
- Character-aware models improve visual text rendering, Liu et al. (2023)에서 제안하듯, CLIP과 같은 vocabulary-based tokenizer는 character에 대한 정보가 부족하다고 합니다.
- Diffusion model의 loss는 전반적인 이미지 생성 품질을 올리기 위함이지 text rendering을 휘한 것이 아니라고 합니다.
이를 해결하기 위해 저자들은 AnyText framework, AnyWord-3M dataset을 제안합니다.
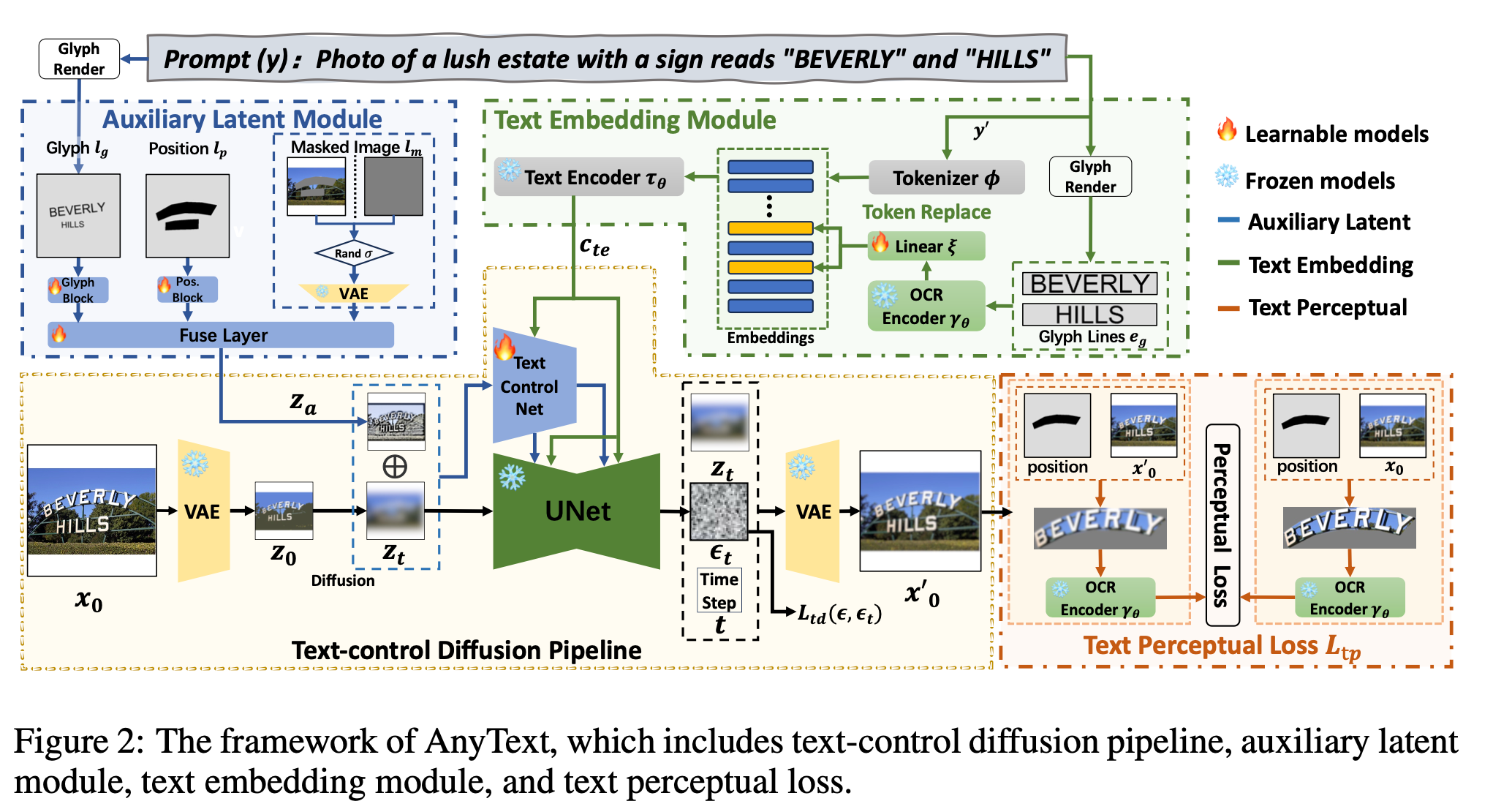
AnyText는 Text-control diffusion pipeline 으로 다음 2가지 구성요소로 이루어져 있습니다.
- Auxiliary latent module : 보조적인 정보(Text glyph, postion, masked image, etc)를 encoding하여 Latent space로 mapping 합니다.
- Text embedding module : OCR 모델을 이용해 Stoke information을 encoding. 이는 tokenizer의 image caption embedding과 합쳐져 text와 background를 자연스럽게 합치도록 돕습니다.
이에 추가적으로 Text perception loss를 제안하여 정확한 text를 rendering 할 수 있도록 한다고 합니다.
저자들의 AnyText는 다른 모델들과 비교했을 때 많은 기능성을 가지고 있다고 합니다.


2. Related Works
Text Generation 관련해서 크게 3가지 연구 측면이 있다고 합니다. 1) Control condition, 2) Text encoder, 3) Perceptual supervision
Control condition
Glyph condition을 latent space에 도입하는 연구들입니다.
- GlyphDraw : Explicit glyph image를 condition으로 사용.
- GlyphControl : Text의 location을 이용해 text를 align하는 방식으로 확장. Font size, text box position을 implicit하게 incorporate.
- TextDiffuser : Character-level segmentation mask를 이용해 condition으로 사용.
저자들은 GlyphControl과 유사하지만, Position과 추가적인 condition으로 masked image를 사용했다고 합니다. 이를 통해 Curved text, irregular region에도 text를 잘 생성할 수 있었다고 합니다.
Text Encoder
Text encoder는 Visual text 생성에 아주 중요한 역할을 합니다. Imagen, eDiff-I, Deepfloyd IF 등의 모델은 large scale LM(e.g. T5-XXL) 등을 사용하여 훌륭한 성능을 보여주었습니다.
하지만 이는 character-blind text encoder이며, 심지어 character level encoder를 사용할 때에도 non-Latin (한국어, 중국어….) 등의 생성에 어려움을 겪는 문제가 있다고 합니다.
- GlyphDraw : 중국어 rendering 문제를 다루기 위해 text encoder를 중국어 이미지에 fie-tuning.
- DiffUTE : text encoder를 pre-trained text image encoder로 교체하여 glyph 추출.
저자들은 semantic, glyph 정보를 통합하여 text encoder를 바꾸는 novel approach를 제안합니다.
Perceptual Supervision
- OCR-VQGAN : Pre-trained OCR detection model을 활용하여 feature를 추출하고, text generation을 supervise.
- TextDiffuser : Character-level segmentation model을 이용해 latent space에서 supervise.
하지만 이런 방법들은 별도의 pre-trained model이 필욜하며, 문자 종류도 제한적이라고 합니다.
저자들은 OCR recognition model을 사용하여, Stroke, Spell을 지정된 위치에서만 supervise한다고 합니다. 더 direct, effective 형태로 supervision을 제공하며 높은 text generation 정확도에 기여한다고 합니다.
3. Methods
3.1. Text-Control Diffusion Pipelines
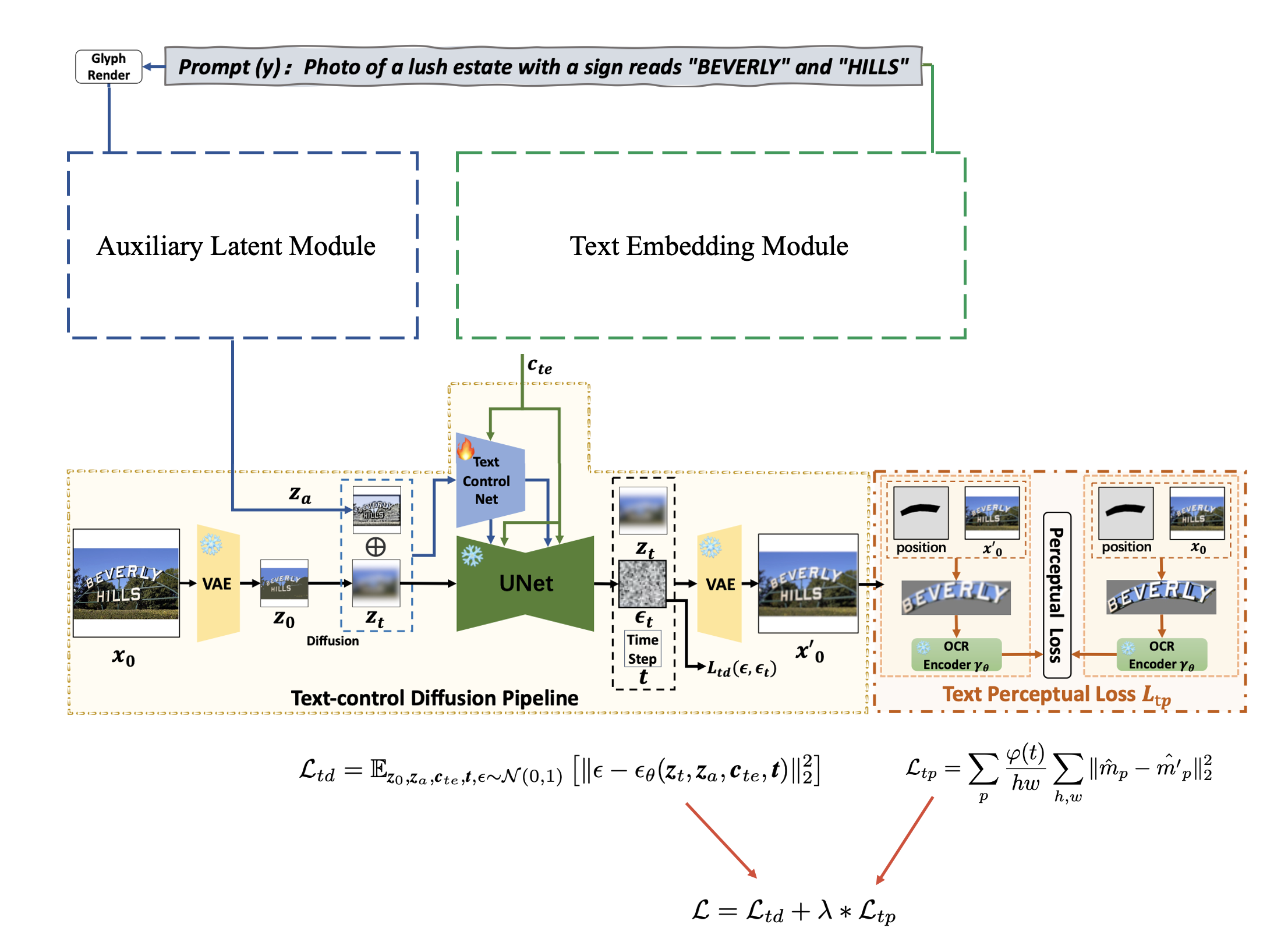
전체적인 pipeline은 위와 같습니다. 이미지를 VAE를 통해 latent space로 보내고, latent space 상에서 Diffusion process를 거침. 이때 auxiliary latent module로 부터 \(z_a\)를 받고, text embedding module로 부터 \(c_{\text{te}}\)를 받아 UNet의 condition으로 활용합니다.
이때 text-control diffusion loss, \(\mathcal{L}_{\text{td}}\)는 다음과 같이 표현할 수 있습니다.
\[L_{td} = \mathbb{E}_{z_0, z_a, c_{te}, t, \epsilon \sim \mathcal{N}(0,1)} \left[ \| \epsilon - \epsilon_\theta(z_t, z_a, c_{te}, t) \|_2^2 \right]\]3.2. Auxiliary Latent Module
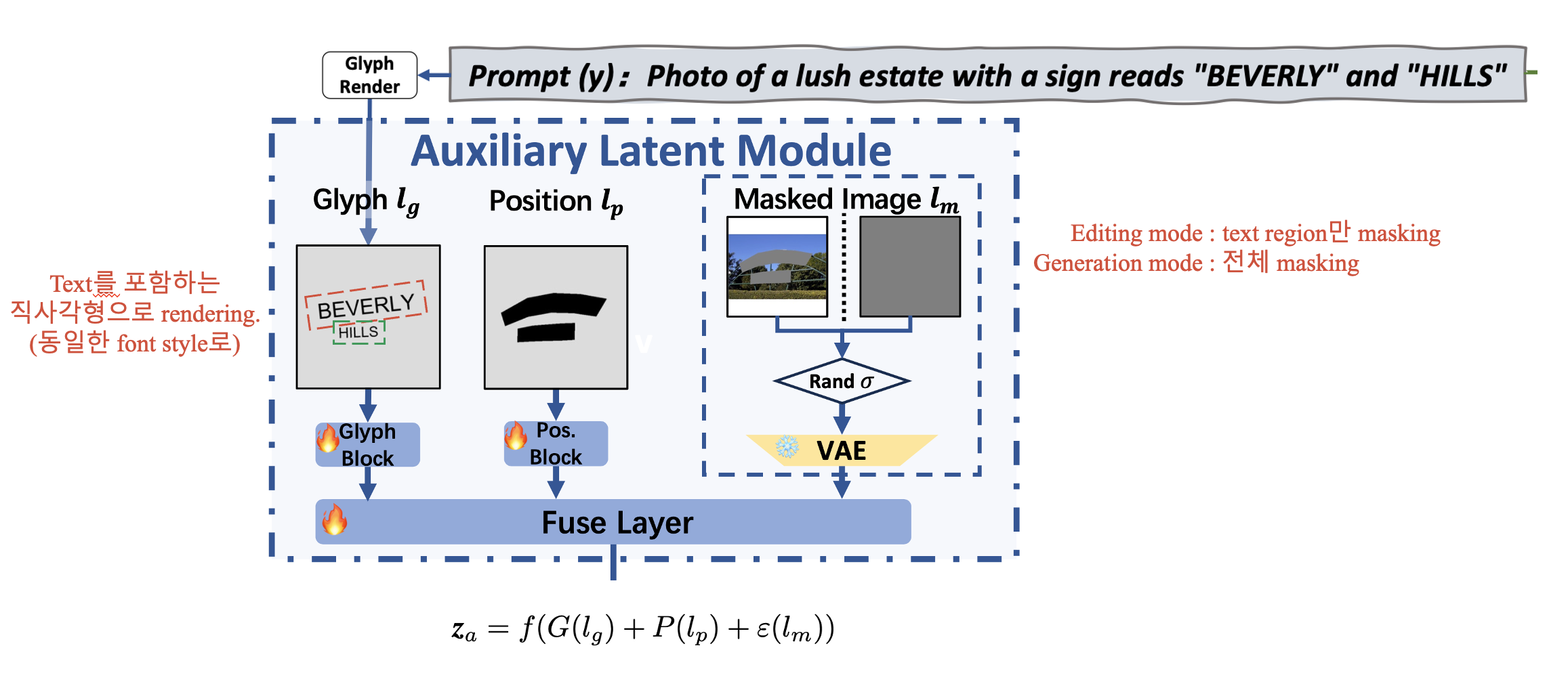
Auxiliary latent module에는 크게 3가지 형태의 condition이 있습니다.
- Glyph \(I_g\) : 위치에 따라 uniform font (Arial Unicode)로 rendering. Curved, irregular 영역에 character를 rendering하는 것은 어려우므로, character를 둘러싸는 직사각형 영역을 기반으로 rendering 하는 방법을 택했다고 합니다.
- Position \(I_p\) : Training phase에서는 pre-trained OCR detector를 이용하거나, manually annotation, Inference 할 때는 사용자의 원하는 input으로.
- Masked Image \(I_m\) : Diffusion 과정에서 유지되어야 하는 부분의 정보를 알려주는 역할.
- Generation : 전체 다 masking
- Editing : Text region만 masking

3.3. Text Embedding Module
Text encoder는 caption의 semantic 정보를 추출하는 건 잘 하지만, rendering 될 text의 semantic 정보는 negligible….
또한 대부분의 pre-trained text encoder는 Latin-based data로 학습했기 때문에, Non-Latin 계열 text에서 성능이 떨어진다고 합니다.
이에 저자들은 Glyph line을 image로 rendering하고, glyph information을 encoding하여, caption token의 special placeholder embedding을 (“ “로 감싸져 있는 부분) 대체하는 방식을 제안합니다. Language-specific encoder를 사용하는 것이 아닌, image rendering을 이용하여 multilingual text에서 상당한 개선을 보였다고 합니다.
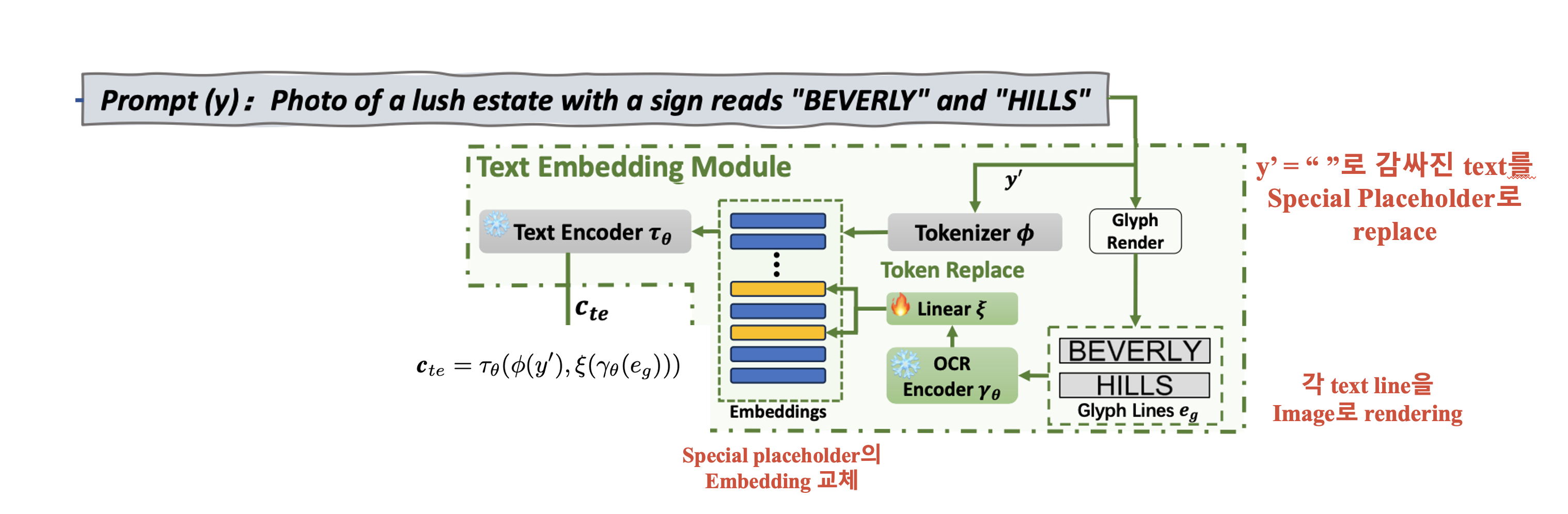
\(y'\)은 text prompt \(y\)에서 “” 로 감싸진 부분을 special placeholder로 처리한 것을 의미한다고 할 때, tokenization, embedding lookup 을 거친 caption embedding은 \(\phi(y')\) 로 표현할 수 있습니다.
또한 각 text line을 image로 rendering한 것을 \(e_g\) 이를 OCR recognition model에 태우면 \(\gamma(e_g)\)이를 caption embedding과 크기를 맞추기 위해 liner layer \(\xi\)에 태우면 최종적으로 \(\xi(\gamma_\theta(e_g))\)를 얻습니다.
Special placeholder의 embedding을 \(\xi(\gamma_\theta(e_g))\)로 교체하고, text encoder에 태우면 최종적으로 다음을 얻습니다.
\[c_{te} = \tau_\theta \left( \phi(y'), \xi(\gamma_\theta(e_g)) \right)\]
3.4. Text Perceptual Loss
Text rendering accuracy를 더 높이기 위해 Text perception loss를 제안합니다. Denoising 과정을 거친 Latent embedding을 VAE의 Decoder를 태워 pixel space로 mapping하고 Input으로 주어졌던 \(I_P\)를 이용해 text region에서 rendering이 잘 되었는지 확인하는 과정입니다. 이때 text 자체만 평가하고, 배경, font style등의 요소를 제외하기 위해 pre-trained OCR recognition을 이용해 text embedding을 얻고 이를 다음 loss 계산에 활용합니다.
\[L_{tp} = \sum_{p} \frac{\phi(t)}{h w} \sum_{h,w} \| \hat{m}_p - \hat{m}'_p \|_2^2\]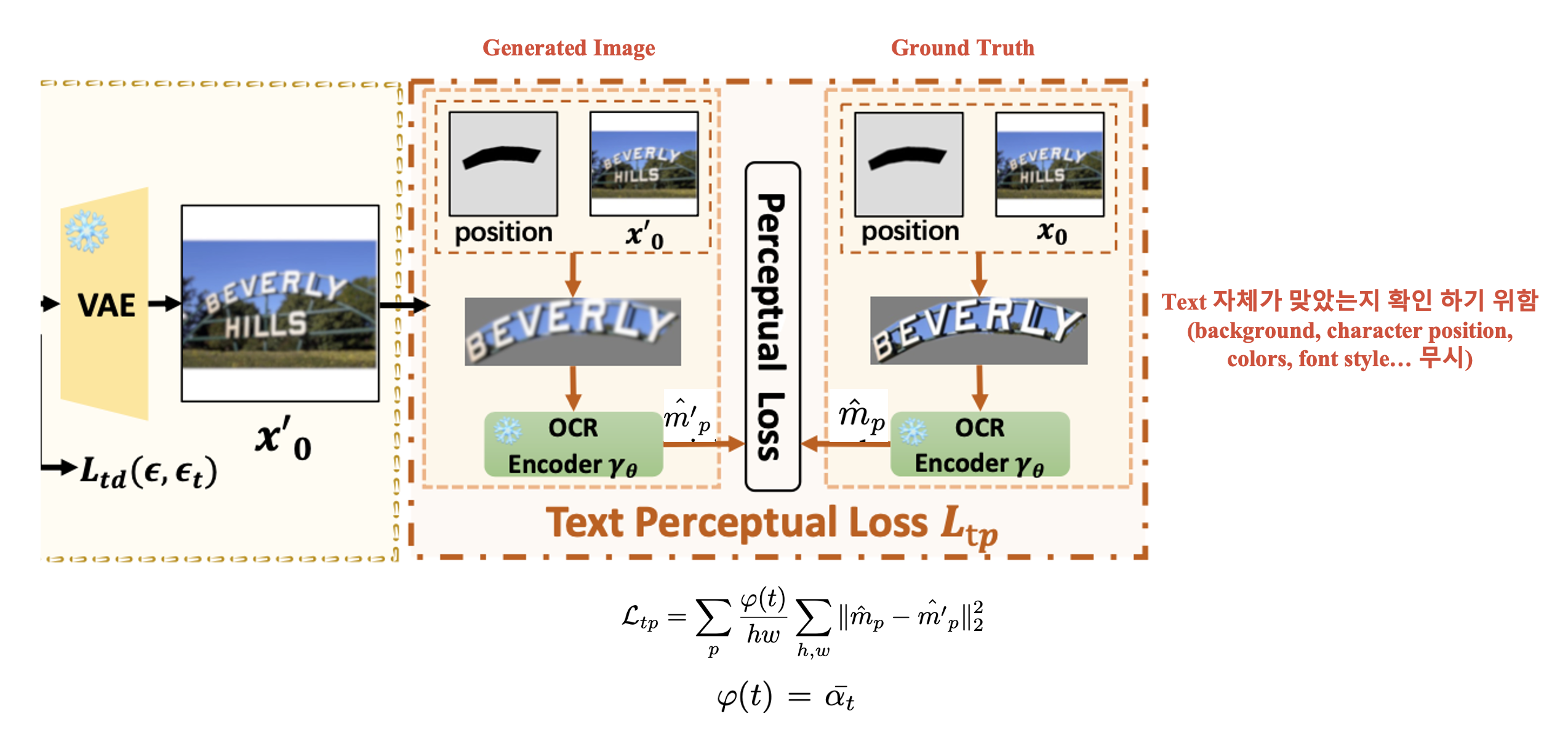
자…. 다시 Model overview입니다.
Dataset and BenchMark
AnyWord-3M 데이터셋:
- 총 303만 개 이미지, Noah-Wukong(Gu et al., 2022), LAION-400M(Schuhmann et al., 2021), 그리고 OCR 인식 작업에 사용되는 ArT, COCO-Text, RCTW, LSVT, MLT, MTWI, ReCTS와 같은 데이터셋이 포함.
- OCR 데이터셋의 경우, 주석 정보(annotation)를 직접 사용했으며, 다른 모든 이미지는 PP-OCRv3(Li et al., 2022) 탐지 및 인식 모델을 사용해 처리. 이후 캡션은 BLIP-2(Li et al., 2023)을 사용하여 새롭게 생성했다고 합니다.

AnyText-benchmark의 경우, 텍스트 생성의 정확도와 품질을 평가하기 위해 세 가지 평가 지표를 사용합니다.
- Sentence Accuracy (Sen. Acc): 지정된 위치에 따라 생성된 텍스트 라인을 자르고, OCR 모델에 입력하여 예측 결과를 얻는데, 예측된 텍스트가 정답과 완전히 일치할 때만 정답으로 간주.
- Normalized Edit Distance (NED): 두 문자열 간 유사성을 측정하는 덜 엄격한 지표를 사용합니다.
- Frechet Inception Distance (FID): OCR만으로는 이미지 품질을 완전히 평가할 수 없으므로, 생성된 이미지와 실제 이미지 간의 분포 차이를 평가.
5. Experiments
5.1. Implementation Details
저자들의 framework는 ControlNet을 기반으로 구현되었으며, model의 초기 weight는 SD 1.5를 사용했다고 합니다.
5.2. Comparisons
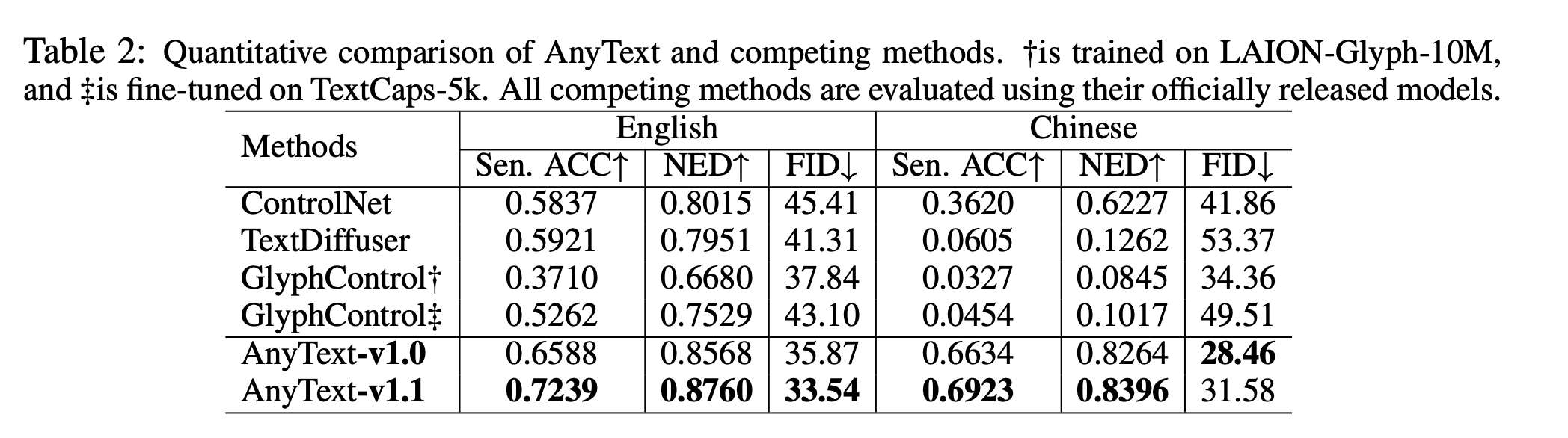
Quantitative Results :
- 중국어 및 영어 텍스트 생성에서 경쟁 방법을 크게 능가.
- OCR 정확도(Sen. ACC, NED)와 사실감(FID) 모두 우수.
- Sen. ACC에서 66% 이상의 정확도 달성, 가장 낮은 FID 점수로 사실성 입증.
Qualitative Results :

영어 텍스트 생성: SD-XL1.0, Bing Image Creator, DALL-E2, DeepFloyd IF와 비교 했을 때 가장 좋은 성능을 보여줍니다
또한, AnyText는 배경과 텍스트 통합에서 뛰어난 성능을 보이며, 돌, 간판, 칠판, 옷 주름 등 다양한 텍스트 스타일에서 우수한 결과를 나타냅니다.

5.3 Ablation Study
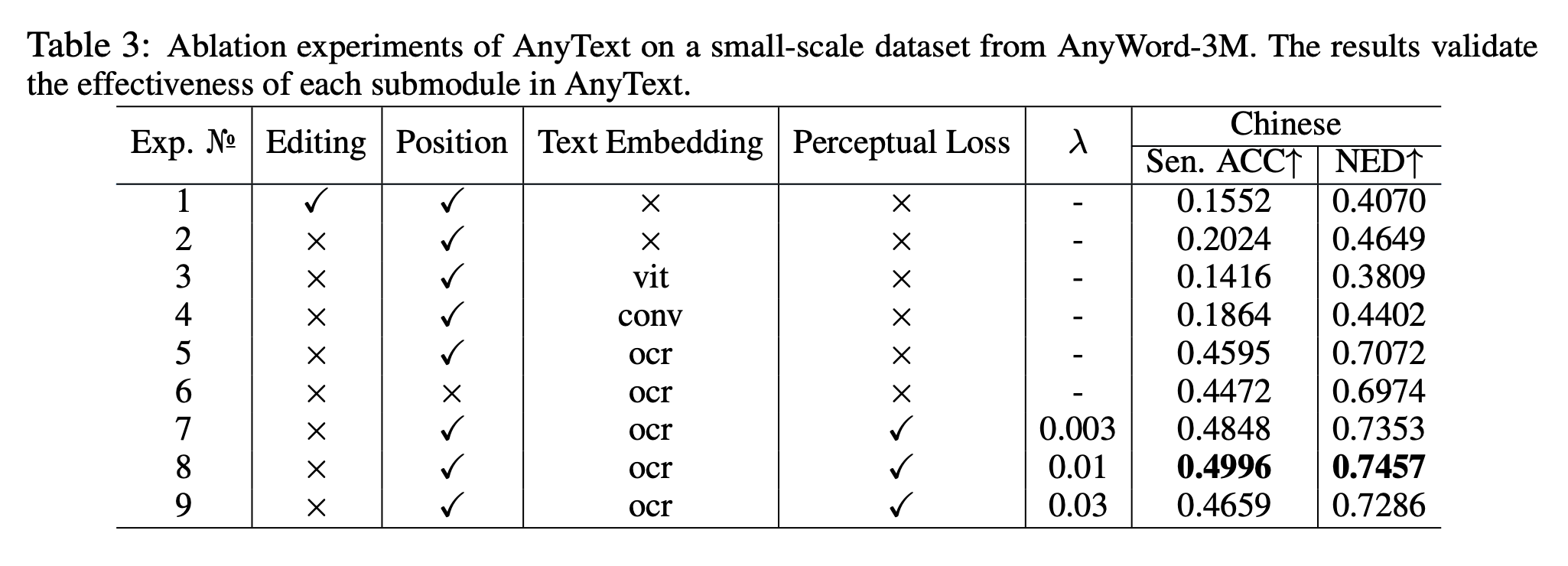
- Text embedding: 사전 학습된 OCR 모델(PP-OCRv3)을 활용해 Sen. Acc 25.7% 향상.
- Position: \(l_p\) 추가로 비정형 영역에서도 성능 향상.
- Perception Loss: Sen. Acc 4.0% 추가 향상.