[Paper Reivew] CLiC: Concept Learning in Context
CLiC은 단일 이미지에서 local한 visual concept을 학습하고, 이를 다양한 목표 객체에 적용하는 In-Context Concept Learning 방법론을 제안합니다.

CVPR 2024 (Highlight). [Paper], [Page]
Mehdi Safaee, Aryan Mikaeili, Or Patashnik, Daniel Cohen-Or, Ali Mahdavi-Amiri
Simon Fraser University, Tel Aviv University
28 Nov 2023
Abstract
본 논문은 단일 이미지에서 객체의 지역적인 시각 패턴(local visual pattern)을 학습하고, 해당 패턴을 가진 객체를 묘사하는 이미지를 생성하는 challenge를 다룹니다.
본 연구에서는 visual concept learning의 최근 발전을 바탕으로, source 이미지에서 visual concept(e.g. 장식)을 얻고, 이를 target 이미지(e.g. 의자)에 적용하는 접근법을 제안합니다.
저자들의 핵심 아이디어는 객체가 속한 넓은 맥락에서 지역적인 visual concept을 학습하는 In-Context Concept Learning을 수행하는 것입니다. Concept learning을 지역화하기 위해, 저자들은 concept이 포함된 마스크와 주변 이미지 영역을 모두 포함하는 soft mask를 사용했다고 합니다.
또한 저자들은 cross-attention 메커니즘과 source objects와 target objects객체 간의 대응 관계를 활용하여 학습한 concept을 target 이미지의 특정 위치에 배치하는 방법을 소개합니다.
TL;DR
CLiC은 단일 이미지에서 local한 visual concept을 학습하고, 이를 다양한 목표 객체에 적용하는 In-Context Concept Learning 방법론을 제안합니다.
1. Introduction
단일 이미지에서 그럴듯한 local concept을 학습하고, 이를 다른 이미지에 적용하는 것은 lack of context 때문에 매우 어려운 task입니다. 특히 shape’s context를 학습해야 하는 경우도 있기 때문에 Break-A-Scene 같이 isolation 시키는 방식들은 한계가 있다고 합니다.
저자들은 visual concept in-context를 위해 personalization method (token \(v^*\)를 학습하는 방법)을 사용했다고 합니다. 이때 mask는 binary mask가 아니라, in-mask concept과 out-mask concept를 모두 고려하기 위해 soft mask를 사용했다고 합니다.
저자들은 Cross-attention, source와 target object의 correspondences등을 이용했으며, 저자들은 특정 concept를 구현하는 여러 객체가 있는 경우, 공통된 concept를 자동으로 식별하는 과정을 제시합니다. 이를 통해 소스 이미지에서 concept를 수동으로 선택할 필요성을 없앴다고 합니다.
2. Related Work
Textual Inversion, DreamBooth1: Personalization을 시도한 연구. 단일 개념을 학습하기 위해 텍스트 토큰을 학습
Custom Diffusion: Diffusion U-Net의 cross-attention만 fine tune하는 방식을 사용. 이때 OFT, LoRA, SVDiff 같은 방법들을 이용해 효율적인 parameter update
PerFusion : rank가 1인 key-locking mechanism 제안. 효율적이고 빠른 update
- Break-A-Scene : 단일 이미지에서 사용자 정의 마스크를 사용해 여러 concept을 학습. 특히,
- 마스크된 diffusion loss사용.
- 학습된 토큰의 Cross-attention map을 Input mask에만 제한
- RealFill2: Inpainting diffusion model을 몇 장의 reference 이미지로 fine tuning. 하지만 Base object의 concept들의 상대적인 크기는 잘 학습이 안된다고 합니다.
또한 최근에 image editing을 위해 diffusion model의 intermediate feature를 이용하는 연구가 많다고 합니다.
- Prompt2Prompt: Cross-attention layers를 조작함으로써, 이미지의 특정 부분을 편집할 수 있다는 것을 발견.
- Attend-and-Excite : Diffusion model은 cross-attention map을 조작함으로써, text prompt에 있는 모든 객체에 attend 할 수 있다는 것을 발견
- 그밖에.. : text token과 cross-attention map을 최적화하여, semantic correspondence나 segmentation이 가능함을 확인했다고 합니다.
저자들은 “In-Context Concept Learning”을 한다고 강조합니다. Cross-attention map을 사용해 학습된 토큰을 source 이미지의 학습된 visual concept에 맞게 localize하고, 이를 target 이미지에 배치한다고 합니다.
3. Method
다시 한번 저자들의 목표를 정리해보자면, 입력으로 다음을 받아, local한 concept을 학습하는 것입니다.
- source image, \(I_s\)
- user prompt, \(P_s\)
- 학습되거나 user가 제공한 마스크 \(M_s\)
저자들은 Custom Diffusion을 기반으로 텍스트 토큰 \(v^*\)을 최적화하고, T2I 모델의 cross-attention 레이어를 동시에 fine-tune 합니다. In-Context에서 concept을 학습하기 위해 저자들은 \(\ell_{att}\), \(\ell_{context}\), \(\ell_{RoI}\)를 합친 multiple loss를 제안합니다.
이렇게 학습한 concept는 이를 포함한 이미지를 새로 생성하거나, 주어진 RoI를 수정하는 방식으로 활용할 수 있다고 합니다.
3.1. In-Context Concept Learning
저자들은 Custom Diffusion를 base로 소스 이미지에서 in-context 개념을 학습하기 위해 텍스트 토큰 \(v^*\)을 최적화하고 T2I diffusion 모델의 cross-attention layers를 fine-tune 합니다.
이때 세 가지 손실 함수가 사용됩니다.
Cross-attention loss, \(\ell_{att}\): Cross-attention loss는 모델이 관심 영역(RoI)에 집중하도록 유도하는 역할입니다. \(\ell_{att} = E(x_t, t) \left[ \lVert CA_\theta (v^*, x_t) - \text{Resize}(M_s) \rVert_2^2 \right]\) 여기서, \(CA_\theta (v^*, x_t)\)는 노이즈가 섞인 latent \(x_t\)와 토큰 \(v^*\)의 cross-attention map을 의미합니다.
Context Loss, \(\ell_{con}\): In-Context concept learning을 위한 loss입니다. 더 큰 객체 내에서 맥락에 맞게 복원되도록 도와줍니다.
- RoI Loss, \(\ell_{RoI}\): 개념을 특정 객체에 과적합하지 않도록 하여 일반화 가능성을 높입니다. 추가적으로 concept의 기하학적으로 미묘한 차이를 얻는데 도움을 준다고 합니다.
위 loss를 모두 사용해 최종 loss를 정의합니다.
\[\ell_{tot} = \ell_{context} + \lambda_{att} \ell_{att} + \lambda_{RoI} \ell_{RoI}, \quad \text{where } \lambda_{att} = \lambda_{RoI} = 0.5\]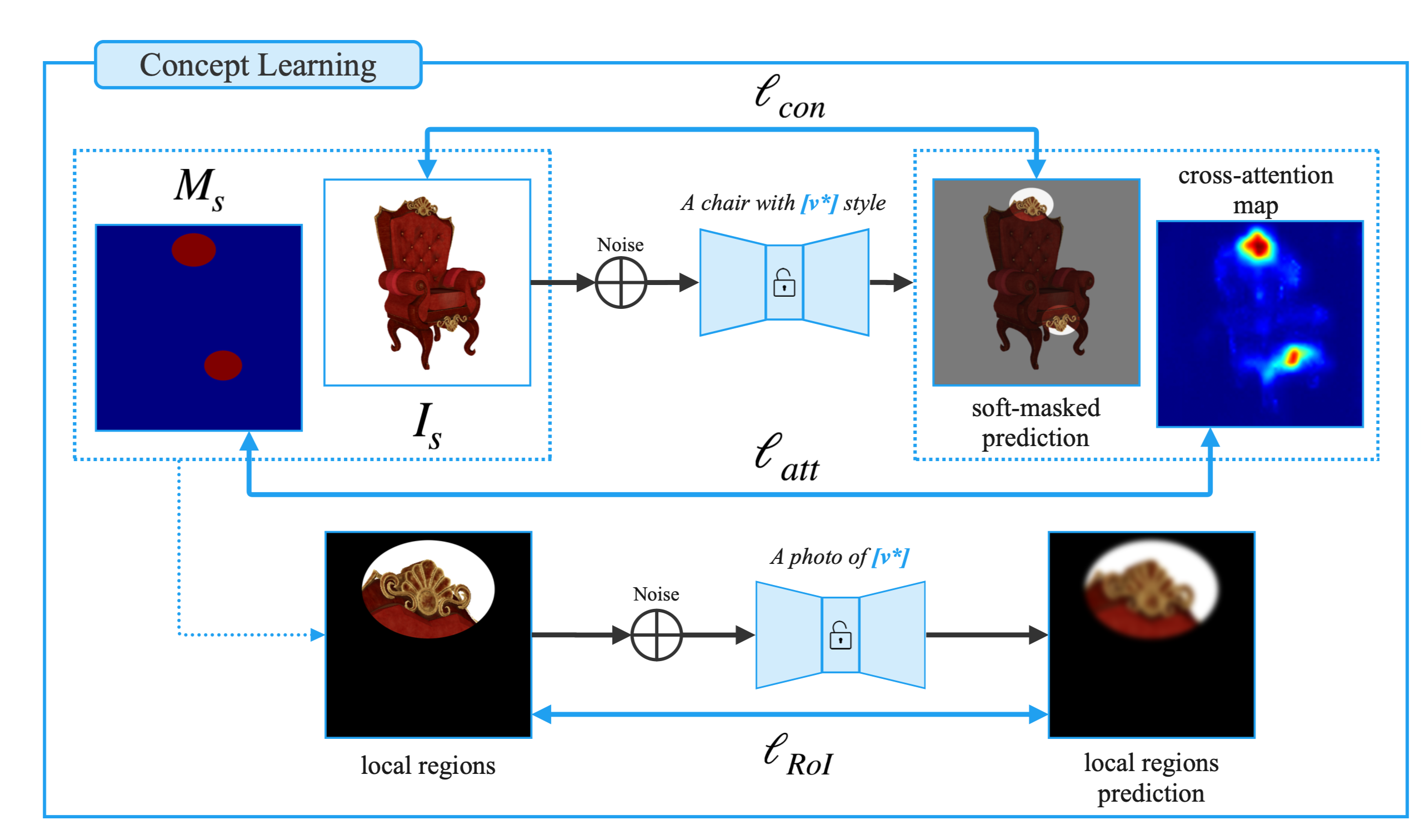
3.2. Concept Transfer
저자들은 학습한 concept을 다른 객체의 RoI에 전달(Transfer)하기 위해 maksed blended diffusion editing 방법론을 사용했다고 합니다.
Blended Diffusion3에서는 masking 영역을 denoising하는 과정에서 noise가 석인 mask 밖영역을 합쳐 사용합니다. 이를 통해 target image와 background image를 자연스럽게 생성해냅니다.
또한 저자들은 Attend-and-Excite의 방법론을 사용해 cross-attention gudiance를 제안합니다. 이를 통해 수정하는 정도를 조절할 수 있었다고 합니다. (\(v^*\)에 해당하는 cross-attention map은 증가시키고, 나머지 영역은 감소하도록 조절)
Blended Diffusion Editing
저자들의 목표는 주어진 이미지 \(I_{tg}\)와 대응 되는 마스크 \(M_{tg}\)을 받아, \(I_{tg} \odot M_{tg}\)영역을 수정하는 것입니다.
- 먼저 target image를 인코딩해 \(x_{tg}\)를 얻고, initial time step, \(t_{start}\)(5~15)을 정합니다.
- \(T- t_{start}\)에 해당하는 nosie를 더해 \(x_{tg}'\) 을 얻습니다.
- \(0 < t < t_{start}\) 동안 belended ouput을 계산합니다.
Cross-AttentionGuidance
- \(x_t'\)를 얻은 후, \(v^*\)토큰의 attention map \(CA_\theta(v^*, x_t')\)를 뽑아냅니다.
- 이후 \(x_t'\)를 다음 식을 통해 업데이트하여, \(M_{tg}\)내에서 \(v^*\)의 attention을 증가시킵니다. \(x^{\prime\prime}_{t} = x^{\prime}_{t} - \eta \nabla_{E} \left[ \| \text{CA}_{\theta}(v^*, x^{\prime}_{t}) - M_{\text{tg}} \|_2^2 \right]\)

3.3 RoI Matching
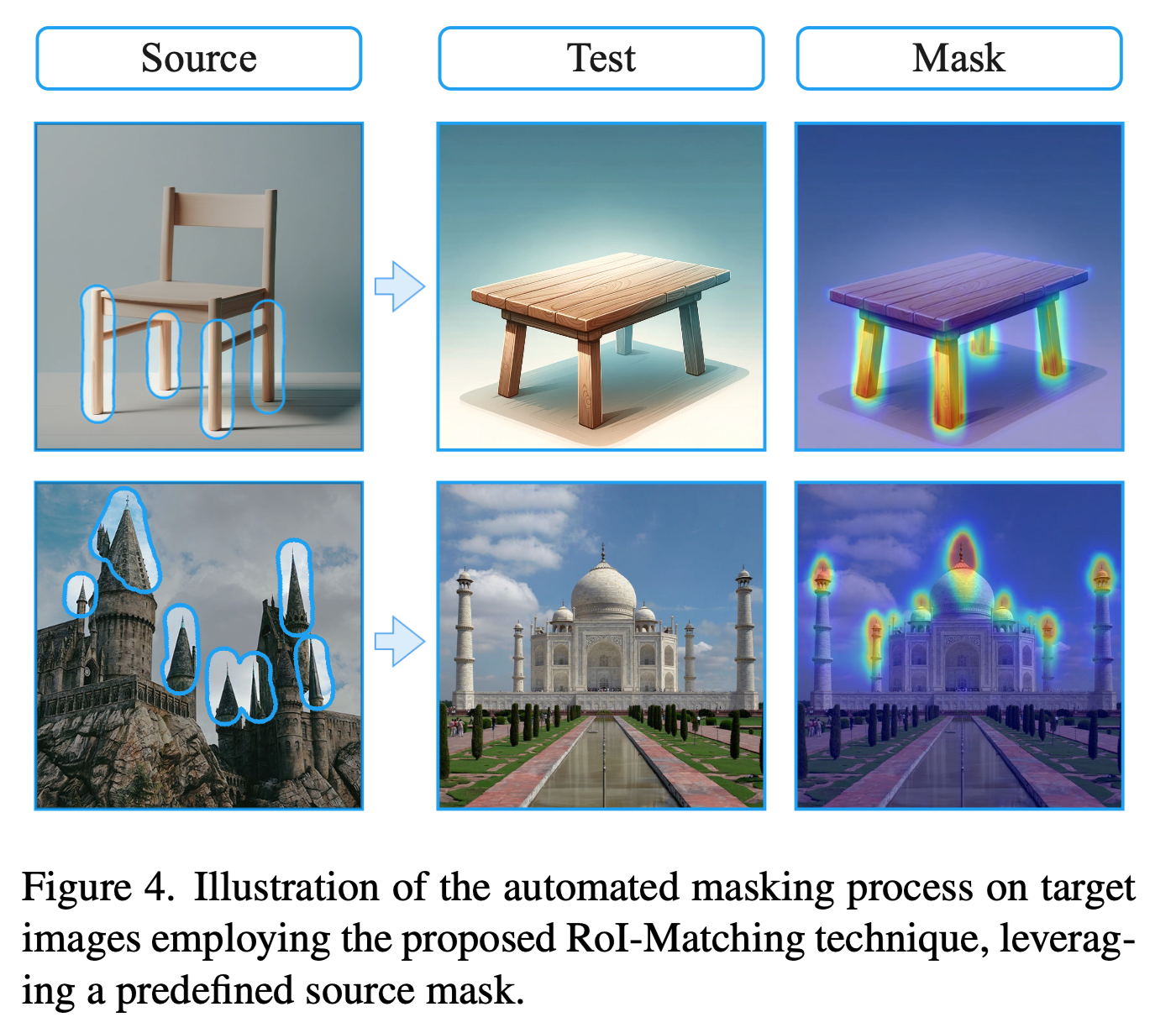
Automatic Target Mask Extraction :
타깃 이미지에서 소스 입력 마스크에 따라 마스크를 자동으로 추출하는 방법입니다.
- 새로운 토큰 \(w^*\)를 텍스트 인코더에 추가하고, \(v^*\)로 initialize합니다.
- “a \(w^*\) region of an OBJECT” 라는 프롬프트에서 \(l_{att}\)를 최소화 하도록 학습합니다. (OBJECT는 source 이미지의 base object)
- 최적화 후, Target 이미지나 다른 소스 이미지에 토큰을 적용하여 denoising 과정을 실행, \(w^*\)의 어텐션 맵을 target 마스크로 사용합니다.
이 과정을 통해 모델이 타깃 이미지나 소스 이미지의 일치하는 부분을 자동으로 분할하는 방식으로 동작하게 된다고 합니다.
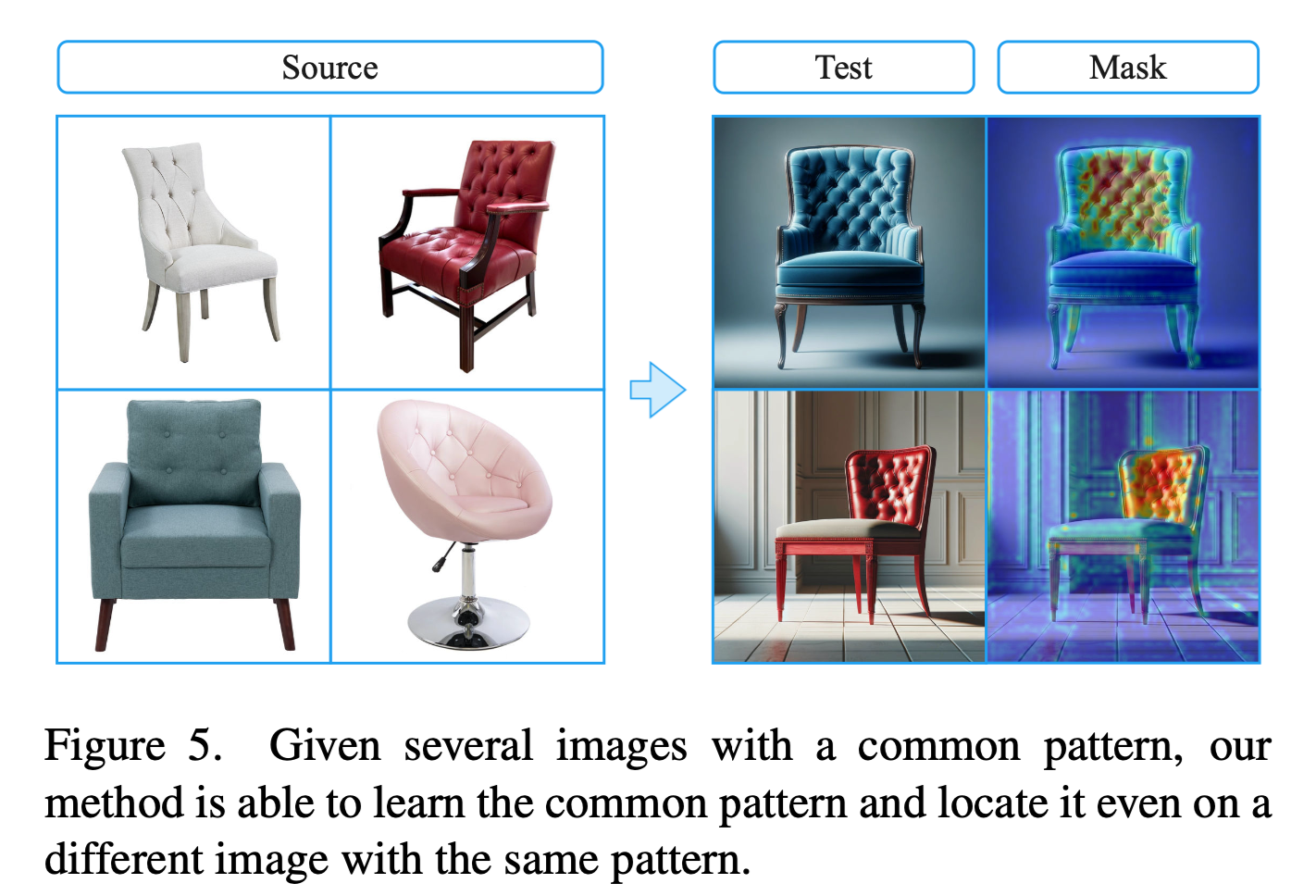
Automatic Source Mask Extraction
여러 개의 소스 이미지가 있을 때 공통된 개념을 자동으로 식별하는 방법입니다.
- 새로운 토큰 \(w^*\)을 텍스트 인코더에 추가하고,
- “An OBJECT with \(w^*\)style”라는 프롬포트에서 \(w^*\)의 임베딩을 cross-attention 모듈과 함께 diffusion loss로 최적화
- 최적화 후, \(w^*\)의 attention map을 source mask로 사용.
이를 통해 여러 객체의 이미지가 있는 경우에는 자동으로 마스크를 추출할 수 있지만… unique concept의 경우 source 마스크를 직접 제공하는 것이 더 간단하다고 합니다.
4. Results and Comparisons
4.1. Qualitative Results
Editing
- 제안된 기법은 동일한 이미지 내에서, 또는 다른 클래스의 객체에도 다양한 개념을 성공적으로 전이함.
- 예를 들어, 한 이미지에서 서로 다른 패턴을 학습하여 타깃 이미지에 각각 전이한 결과, 색상이나 형태의 누락 없이 잘 동작
- soruce와 target 도메인의 차이가 크더라도 소스 이미지의 concept이 잘 반영

Generation
저자들은 학습된 개념을 포함한 객체를 생성하기 위해 두 단계의 생성 전략을 사용했습니다.
- \(t_s = 5\) step 동안은 사전에 학습된 diffusion 모델을 사용해 일반적인 이미지를 생성하고, (“a photo of an OBJECT”)
- 이후 학습된 개념의 디테일을 통합하기 위해 fine tune된 UNet을 이용해 이미지를 생성. (“a photo of an OBJECT, with \(v^*\) style”)
이 과정을 통해 특정 concept(특정 패턴이나 디테일)을 효과적으로 유지하면서 다른 객체에도 활용할 수 있는 결과물을 보여줍니다.

4.2. Comparisons
- Custom Diffusion: Cross-attention block과 토큰 \(v^*\)을 최적화하여 concept을 학습하는 방법론입니다. Source 이미지의 concept을 제대로 학습하지 못한다고 합니다.
- Break-A-Scene: 단일 이미지에서 여러 개념을 학습하지만, context 제약이 없기 때문에 패턴을 독립적인 객체로 학습해버림. 이로 인해 전이 과정에서 색상 및 기하학적 artifact가 발생
- RealFill: Inpainting Stable Diffusion을 사용하여 마스크된 영역을 채우는 방식이지만, 두 가지 문제가 있다고 합니다.
- 타깃 마스크에 의해 정보가 손실되어, 타깃 객체의 기하학적 형태와 색상을 유지하지 못함.
- context 학습이 없기 때문에, 개념을 일관성 있게 배치하지 못하고, 전체 마스크 영역을 채워버리는 문제

4.3. Ablation study
Loss Ablations:
- RoI 손실 (\(\ell_{RoI}\)) 제거: 개념의 기하학적, 구조적 특징이 손실됨. 타깃 객체의 뒷좌석 부분에서 이러한 손실이 두드러짐.
- Attention 손실 (\(\ell_{att}\)) 제거: 타깃 객체의 다리나 좌석 등 원하지 않는 부분에서 수정이 발생함.
- Context 손실 (\(\ell_{con}\)) 제거: 개념의 기하학적 디테일과 구조가 손실되고, 다리 사이의 전환 부분과 같은 원치 않는 영역에 개념이 전이됨.

Cross-Attention Guidance:
- 제안된 cross-attention guidance를 사용해 개념이 타깃 이미지에서 일관되게 위치하도록 조절함.
- 가이던스 스텝 크기 \(\eta\)를 변경함으로써 타깃 이미지 내 개념의 강도를 조절 가능.

5. Discussion and Conclusions
저자들은 이미지 간의 visual concept을 learning하고 transfer 과제를 해결했습니다. 특히 local한 visual concept를 context 내에서 학습하고 적용하는 데 중점을 두었습니다. 저자들의 주요 contribution은 다음과 같습니다.
Concept Learning 과정에서 새로운 loss 제안. \(\ell_{tot} = \ell_{context} + \lambda_{att} \ell_{att} + \lambda_{RoI} \ell_{RoI}, \quad \text{where } \lambda_{att} = \lambda_{RoI} = 0.5\)
Concept Transfer에서 Blended Diffusion 과정과 Cross-attention Guidance를 이용해 target 이미지에서 concept이 얼마나 반영될 지 조절 가능.
Automatic Mask Extraction를 통해 전반적인 workflow를 간소화할 수 있음.
Limitations:
- 타깃 이미지와 소스 이미지의 도메인이 크게 다를 경우 성능이 저하될 수 있음.
- 최적화 과정이 시간이 오래 걸려 실시간 응용에는 적합하지 않음.
