[Paper Reivew] Multi-Concept Customization of Text-to-Image Diffusion
새로운 (single- or multiple-) concept을 Cross-attention layer의 Key, Value matrix만 fine-tune하여 학습할 수 있는 CustomDiffusion을 제안합니다.

CVPR 2023 [Paper] [Page]]
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, Jun-Yan Zhu
Carnegie Mellon University, Tsinghua University, Adobe Research
20 Jun, 2023
TL;DR
새로운 (single- or multiple-) concept을 Cross-attention layer의 Key, Value matrix만 fine-tune하여 학습할 수 있는 CustomDiffusion을 제안합니다.
1. Introduction
유저가 제공하는 몇 장의 이미지로, 새로운 이미지를 생성하는 것은 많이 연구되고있는 분야입니다. 이전 연구들의 문제점을 크게 보면 다음과 같습니다.
Language drift : 예를들어 “moongate”라는 concept을 학습하면, “moon”, “gate”등의 concept을 잊는다고 합니다.
Overfit에 취약
저자들은 이러한 문제를 해결하면서, 더 어려운 문제인 compositional fine-tuning 문제를 다루는 CustomDiffusion을 제안합니다. 아주 적은 parameter (Cross-attention layer의 Key, value matrix)만을 fine-tune하면서 효율적이고 성능이 좋은 방법이라고 주장합니다. 또한 model forgetting을 막기위해 저자들은 target text와 유사한 real image를 Retrieval하여 regularization set으로 활용하는 방법도 제안합니다. 또한 multiple-concept을 다룰 때, 동시에 학습하거나 따로 학습한 모델을 합치는 방법 모두 사용할 수 있다고 합니다.
저자들의 contribution을 요약하자면…
- Cross-attention layer의 Key, value matrix만을 fine-tuning하여 효율적으로 concept 학습
- Target text와 유사한 text를 갖는 real image를 regularization set으로 활용.
- Jointly training 혹은 따로 학습한 weight를 optimization을 통해 Multiple concept 학습 가능.

2. Related Work
생략
3. Method
 핵심 아이디어 요약
핵심 아이디어 요약
3.1. Single-Concept Fine-tuning
저자들이 Rate of change of weights, \(\Delta_l = \frac{\|\theta_l' - \theta_l\|}{\|\theta_l\|}\)를 분석한 결과 전체 파라미터 수의 아주 작은 부분을 차지하고 있는 cross-attention layer의 변화가 가장 컸다고 합니다.

이런 관찰에서 저자들은 Cross-attention의 condition으로 들어가는 text feature가 Key, Value matrix에만 영향을 받으므로 Key, Value matrix만 fine-tuning했다고 합니다.

뒤의 실험 결과에서 Key, Value matrix만 fine-tuning해도 충분하다는 것을 보입니다.
또한 저자들은 fIne-tuning 방법의 문제점인 language drift(“moongate”라는 concept을 학습하면, “moon”, “gate”등의 concept을 잊는 것)을 해결하기 위해 fine-tuning 과정에서 target image와 비슷한 image를 LAION-400 \(\text{M}\)에서 retrieval하여 regularization에 사용했다고 합니다.

3.2 . Multiple-Concept Compositional Fine-tuning
- Joint training on multiple concepts 각 concept의 dataset을 모아 jointly training 하는 방식.
- Constrained optimization to merge concepts 이미 각 concept을 학습한 model이 있으면 이를 적절히 합쳐서 Multiple Concept을 학습할 수 있다고 합니다.
위 식은 Lagrange multipliers 방법을 통해 closed-form solution을 얻을 수 있다고 합니다.
\[\widehat{W} = W_0 + \mathbf{v}^\top \mathbf{d}, \quad \text{where} \quad \mathbf{d} = C(C_{\text{reg}}^\top C_{\text{reg}})^{-1}, \quad \text{and} \quad \mathbf{v}^\top = (V - W_0C^\top)(\mathbf{d}C^\top)^{-1}.\]직관적으로 생각하면, 위 방법은 target caption에 있는 단어를 각 concept을 fine-tune한 모델의 결과에 일관적으로 mapping하도록 original matrix를 update하는 것이라고 합니다.
4. Experiments
4.1. Single-Concept Fine-tuning Results
- Qualitative evaluation

Textual Inversion보다 성능이 우수하며, DreamBooth와 유사한 성능을 보이지만 훈련 시간과 모델 저장 용량 측면에서 더 효율적입니다. (훈련 속도 약 5배 빠름, 75MB vs 3GB)
- Quantitative evaluation
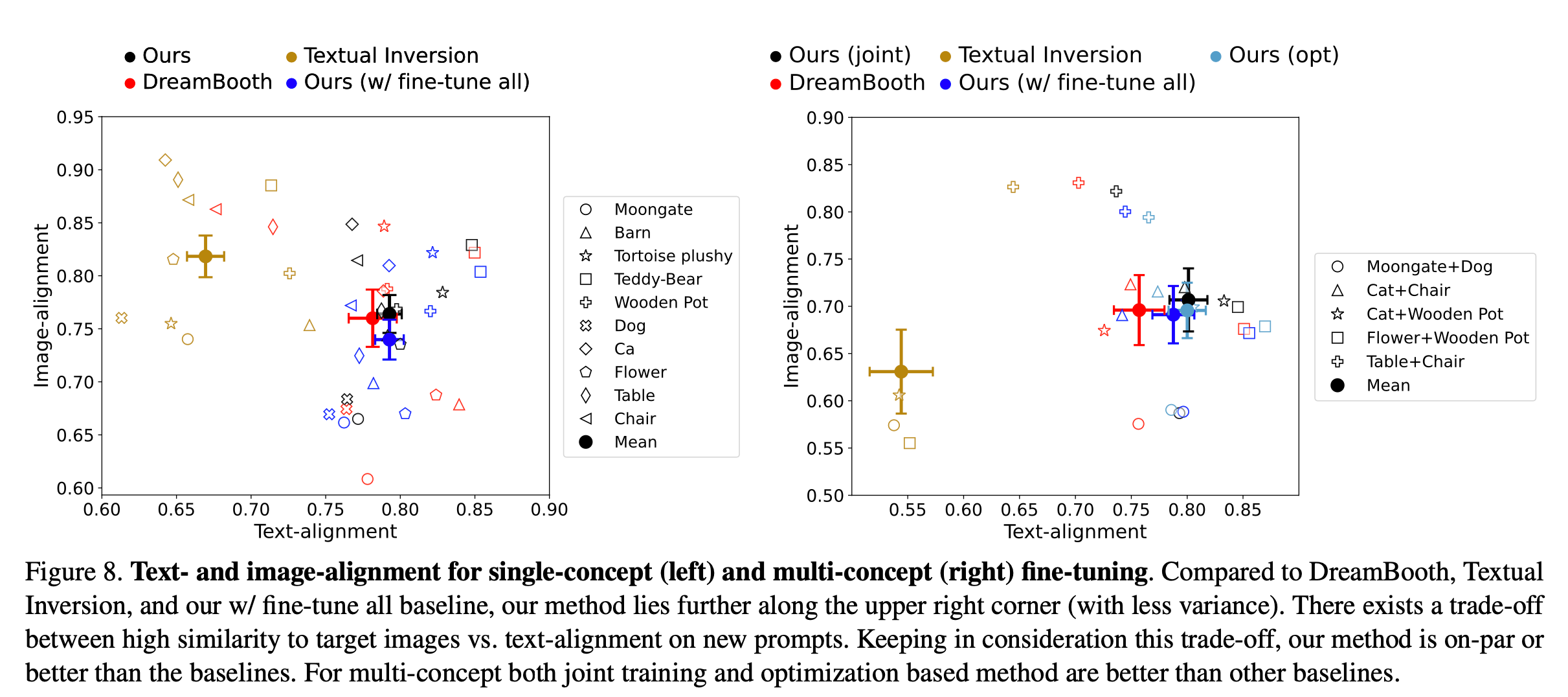
Custom Diffusion은 모델의 모든 가중치를 세부 조정한 DreamBooth 방식과 유사한 성능을 보이며, 계산 및 시간 효율성이 더 높음.
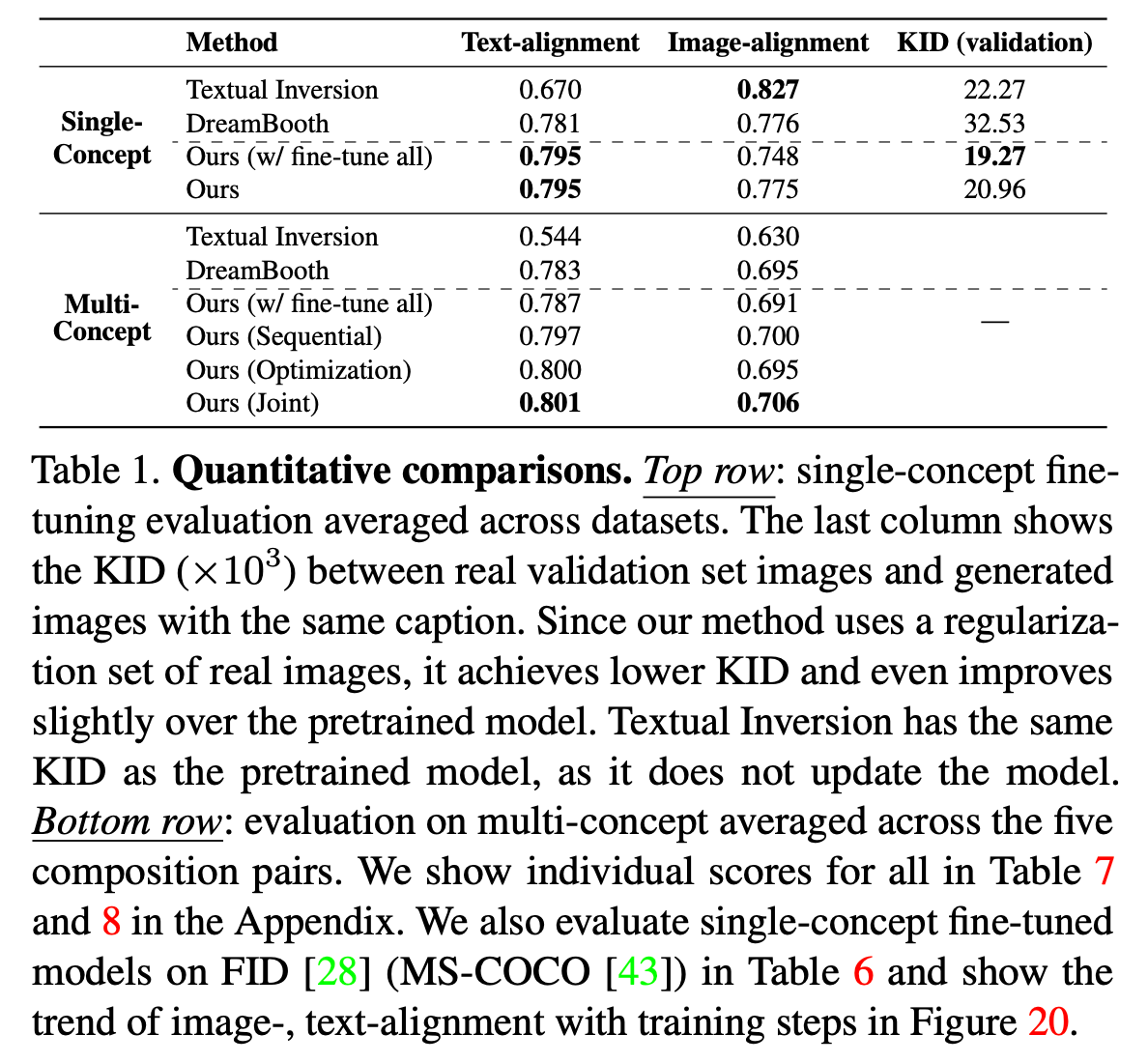
4.2. Multiple-Concept Fine-tuning Results

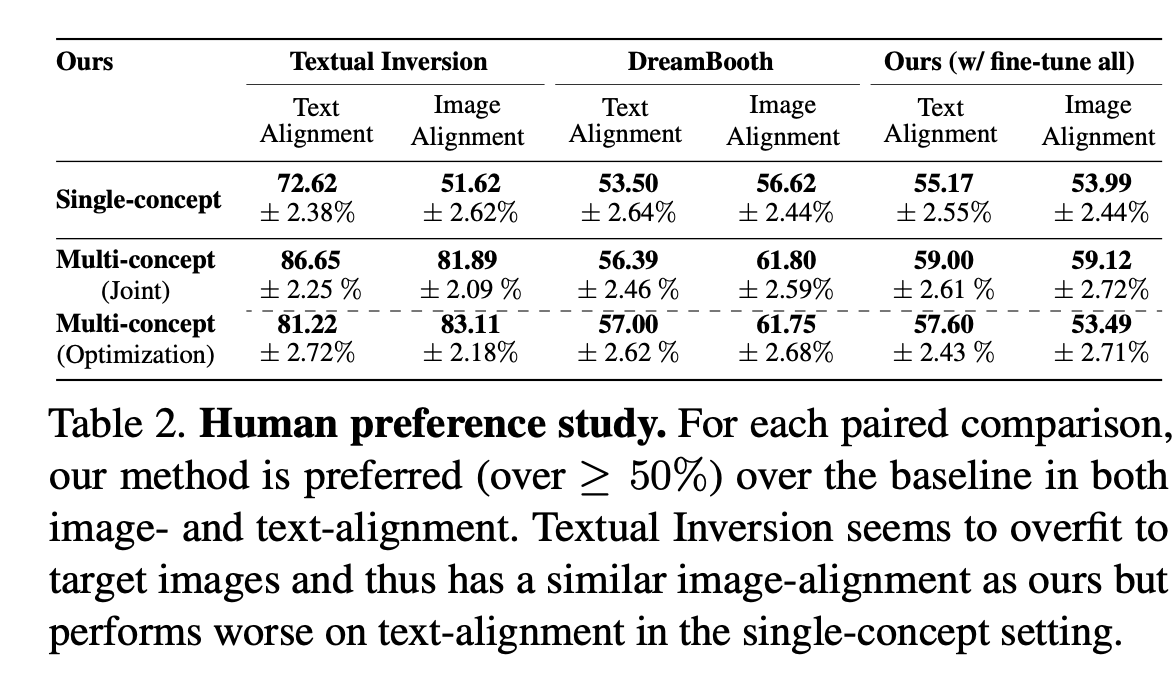
4.3. Human Preference Study
- Text-alignment: “어느 이미지가 텍스트와 더 일치하는가?”
- Image-alignment: “어느 이미지가 목표 이미지와 더 잘 일치하는가?”
4.4 Ablation and Applications
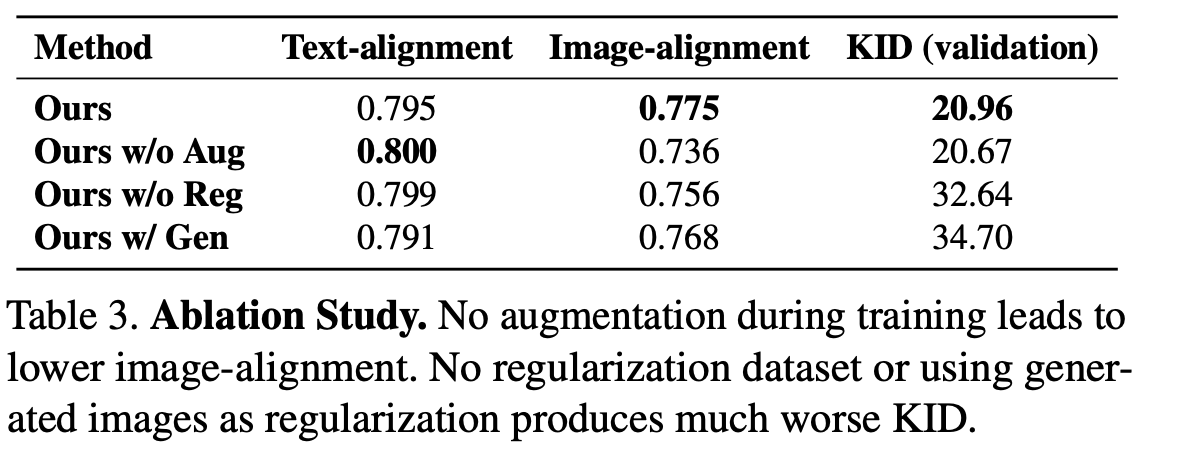
- Generated images as regularization (Ours w/ Gen)
Regularization set으로 generated image 사용한 결과 성능이 떨어졌음. 저자들의 주장대로 real-image를 retrieval 하여 Regularization set으로 사용하는 것이 효과적.
- Without regularization dataset (Ours w/o Reg) 정규화 데이터셋 없이 학습을 진행한 결과 language drift가 심해졌다고 합니다.
- Applications
 특정 스타일에 대해 fine-tuning 가능.
특정 스타일에 대해 fine-tuning 가능.
 fine-tuned 모델을 이용해 image editing 가능.
fine-tuned 모델을 이용해 image editing 가능.