[Paper Reivew] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
T2I Diffusion의 personalization의 방법론 논문의 리뷰입니다.

CVPR 2023.[Paper] [Demo] [Github]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
Google Research | Boston University
25 Aug 2022
TL;DR
본 논문은 Text-to-Image(T2I) 모델에서 이전까지는 불가능했던 ‘Personalization’을 위한 방법론을 제시한다. 몇 장의 이미지를 입력으로 받아 pretrained T2I model을 finetune하면 특정 대상과 특정 식별자를 학습할 수 있게된다. 이 방법론을 사용해 대상의 key feature를 유지하면서, recontextualization, text-guided view synthesis, aritistic rendering 등을 가능하게 한다.
1. Introduction
최근 Large T2I model들은 전례없는 성능을 보여주는 반면, 주어진 reference subject를 정확히 생성하는데에는 한계가 있다. 이러한 문제의 주된 이유는 표현의 제한성에 있다. 아무리 자세히 text prompt를 작성하더라도 모든 디테일을 설명할 수는 없다.
이런 맥락에서 저자들은 diffusion T2I model의 ‘Personalization’ 방법론을 제안한다. 저자들의 목표는 language-vision 사전을 확장하여, 유저가 원한는 이미지(객체)와 텍스트의 쌍을 이 사전에 추가하는 것이라고 한다.
유저가 몇 장(3~5)의 이미지만 제공한다면, 그 이미지에 있는 객체를 unique identifier를 사용하여 output domain에 포함시키도록 하는 것이다. (e.g., “A [V] dog”)
저자들은 이러한 방법론이 객체의 재맥락화, 특징 수정, art rendering뿐만 아니라, 이전에 불가능했던 다른 방법론의 기초가 될 것이라고 한다;.
2. Method
저자들의 목표는 3~5장의 이미지만 가지고(w/o textual description) 주어진 text-prompt에 맞게 새로운 객체의 이미지를 생성하는 것이다.
2.1. Text-to-Image Diffusion Models
Text-to-Image Diffusion model을 간단히 살펴보자. Text Prompt \(P\)를 text-encdoer \(\Gamma\)에 입력으로 넣어 conditioning vector \(c = \Gamma(P)\)를 이용해 이미지 \(x_{gen} = \hat x_\theta (\epsilon, c)\)를 생성한다 .
Training은 \(z_t:= \alpha_t x + \sigma_t \epsilon\)를 denoising 하도록 squared-loss를 사용한다.
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, t} [w_t \| \hat{x}_\theta (\alpha_t x + \sigma_t \epsilon, c) - x \|_2^2] \end{equation}\]2.2. Personalization of Text-to-Image Models
Designing Prompts for Few-Shot Personalization :
저자들의 목표는 새로운 (unique identifier, subject) set을 ‘implant’하는 것이다. 디테일을 적는 overhead를 줄이기 위해 저자들은 모든 input 이미지를
“a [identifier] [class noun]”
같은 형태로 연결시켰다. 이는 저자들이 pre-trained model의 prior를 이용하면서 저자들의 unique identifier의 embedding을 여러가지 맥락에서 합치기 위해서라고 한다.
Rare-token Identifiers:
“unique”, “special” 같은 영어 단어를 token으로 쓰는 경우 모델이 이를 원래 의미로부터 disentangle 한뒤, 우리가 입력으로 넣어준 객체에 re-entangle하기 때문에 바람직하지 않다고 한다. 비슷하게 random character(“xxy5syt00”)를 직접 사용하는 것도 문제점이 있다고 한다.
이에 저자들은 vocabulary에서 rare token을 찾은 뒤, text space로 token을 바꾸는 방법을 택해, identifier가 strong prior를 갖는 확률을 최소화하도록 했다. (text model과 diffusion model에서 모두 weak prior를 갖는 identifier가 필요함)
구체적으로는 vocabulary에서 rare-token lookup을 수행한 뒤, rare token identifier의 sequnce \(f(\hat V)\)를 얻는다. 그 다음 \(f(\hat V)\)에 de-tokenizer를 사용하여 unique identifier \(\hat V\)를 얻는다.
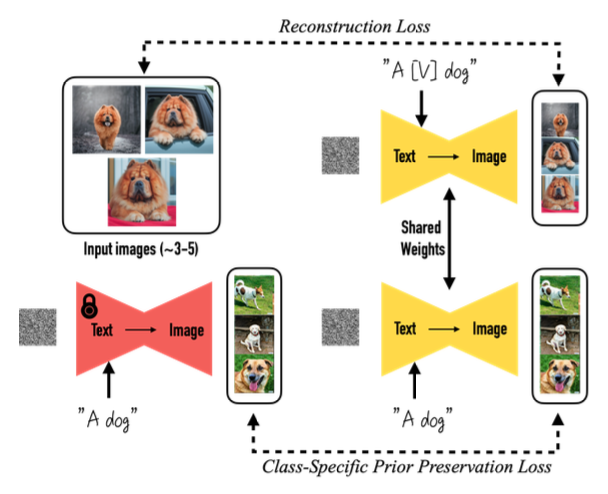
2.3. Class-specific Prior Preservation Loss
저자들의 실험에서 가장 좋은 결과는 모든 layer를 fine-tuning했을 때라고 한다. 이때 text embedding layer까지 fine-tuning하는데 이는 language-drift라는 문제점을 발생시킬 수 있다고 한다.
1. Language Drift 언어 모델에서 발견된 현상으로, 커다란 데이터에서 pre-train된 모델이 특정 task에 대해 fine-tune되면 언어의 맥락적, 의미적 정보를 잃어가는 것을 의미한다. 저자들은 diffusion model에서도 이러한 현상이 일어나는 것을 처음 발견했으며, target subject와 같은 class의 이미지를 생성하는 것을 점점 못하게 되었다고 한다.
2. Reduced output diversity. Diffusion model은 본래 높은 output diversity를 지니고 있다. 하지만 저자들을 적은 이미지로 fine-tune하는 경우, output pose나 view가 제한적이게 된다는 것을 확인했다고 한다. 모델의 training이 길어질수록 이러한 현상이 더 자주 발생했다고 한다.
저자들은 이러한 문제점을 완화하기 위해, autogenous class-specific prior preservation loss를 제안한다. 본질적으로 저자들의 방법론은 모델이 만든 샘플 이미지를 이용하여 supervise하는 것이라고 한다. 그렇게함으로써, few-shot fine-tuning이 되어도 prior를 유지할 수 있다고 한다.
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, \epsilon', t} [w_t \| \hat{x}_\theta (\alpha_t x + \sigma_t \epsilon, c) - x \|_2^2 + \lambda w_{t'} \| \hat{x}_\theta (\alpha_{t'} x_\textrm{pr} + \sigma_{t'} \epsilon', c_\textrm{pr}) - x_\textrm{pr} \|_2^2 ] \end{equation}\]이때 \(\lambda w_{t'} \| \hat{x}_\theta (\alpha_{t'} x_\textrm{pr} + \sigma_{t'} \epsilon', c_\textrm{pr}) - x_\textrm{pr} \|_2^2\) Term은 prior-preservation term이라고 한다.
3. Experiments
3.1. Dataset and Evaluation
30개의 subject, 25개의 text prompt로 구성, subject는 live/object로 구분
Live subject(9개) : 10 recontextualization, 10 accessorization, and 5 property modification prompts
Object(21개) : 20 recontextualization prompts and 5 property modification prompts for objects

3.2. Comparisons
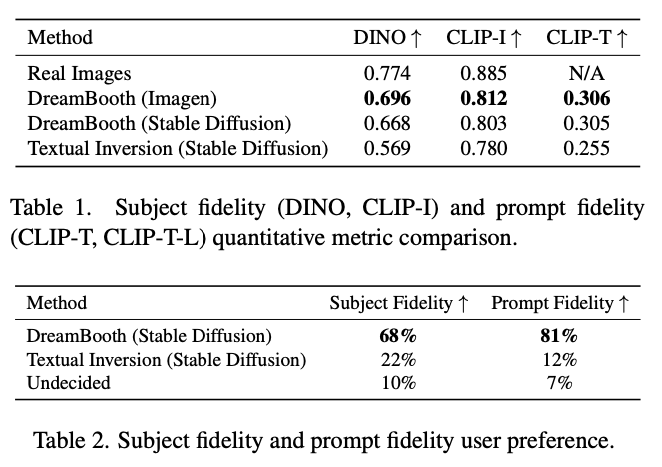
Text-inversion 방식에 비해 훨씬 좋은 성능을 내는 것을 확인했다고 한다.
3.3. Ablation Studies
1. Prior Preservation Loss
 Encouraging diversity with prior-preservation loss
Encouraging diversity with prior-preservation loss
Naive한 fine-tuning은 overfitting 문제가 발생하는데, PPL을 사용하면 다양한 포즈의 샘플이 나오는 것을 확인할 수 있다.
2. Class-Prior 저자들은 (1) with no class noun, (2) randomly sampled inccorect class noun, (3) correct class noun으로 나누어서 ablation study를 진행한 결과, (3) correct class noun 에서 class prior를 잘 이용해 다양한 맥락에서 이미지를 잘 생성했다고 한다.
3.4. Applications
1. Recontextualization “a [V] [class noun] [context description]”와 같은 prompt를 이용해 Recontextualization를 실험했다고 한다.
 Recontextualization. We generate images of the subjects in different environments, with high preservation of subject details and realistic scene-subject interactions
Recontextualization. We generate images of the subjects in different environments, with high preservation of subject details and realistic scene-subject interactions
2. Art Renditions “a painting of a [V] [class noun] in the style of [famous painter]” 혹은 “a statue of a [V] [class noun] in the style of [famous sculptor]” 와 같은 prompt를 이용해 Art Rendition을 실험했다고 한다.
Style transfer(source structure은 유지한채로 스타일만 transfer)와는 다르게 DreamBooth는 의미있고 창의적인 변형이 가능했다고 한다.

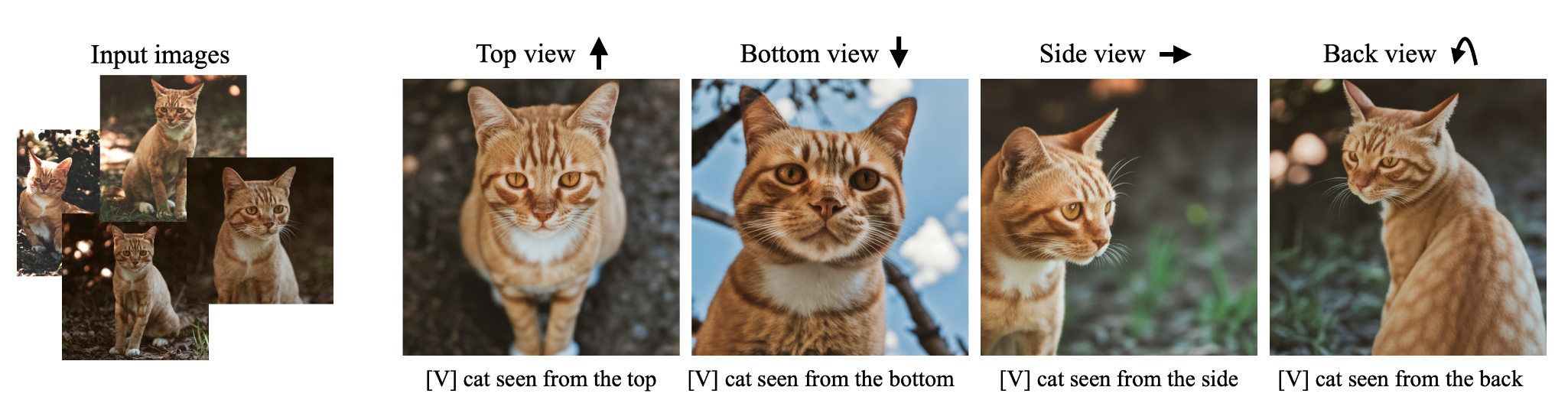
3. Novel View Synthesis 저자들은 모델이 subject의 보지 못한 부분도 class prior 정보로부터 extrapolate를 통해 적절한 이미지를 생성해냈음을 강조한다.
4. Property Modification unique visual feature은 유지하면서 필요한 부분만 적절히 수정하는 것을 확인할 수 있다.

5. Accessorization 주어진 subject의 identity는 유지하면서, 다양한 outfit이나 accessory가 잘 적용된 것을 확인할 수 있다. 
4. Limitations
다만 저자들은 DreamBooth가 (a) text prompt로 주어진 맥락을 제대로 생성하지 못한다는 문제점이 발생하기도 했다고 한다. 가능한 원인으로는 text prompt로 주어진 맥락에 대한 prior가 부족하거나, training data상에서 특정 맥락과 특정 대상이 함께 나타날 확률이 낮아 이미지를 생성하는데 어려움을 겪을 수 있다는 점을 언급했다.
또한 (b) 맥락과 외형이 entangle되는 문제점이 발생하기도 한다. 일정해야 할 subject의 외형이 prompt에 따라 변하는 경우가 이에 해당한다.
마지막으로 promptr가 original setting과 유사할 때 overfitting 문제가 발생한다고 한다.

또한, 다음과 같은 문제점 또한 발생한다고 한다.
- 어떤 대상은 다른 대상보다 학습하기가 더 쉬운 문제
- 드물게 등장하는 대상의 경우, 모델이 다양한 변형을 지원하지 못하는 문제
- 대상의 fideltity 변동성이 있으며, 모델의 prior 강도와 의미적 수정의 복잡성에 따라 생성된 이미지에서 대상의 외형이 왜곡되거나 hallucinated subject가 포함된다는 문제
5. Conclusions
저자들은 몇 장의 이미지(3~5장)만을 이용해 새로운 방식으로 text prompt에 맞는 이미지를 생성해내는 방법론을 제시하였다. 저자들의 핵심 아이디어는 주어진 instance 와 unique identifier 을 바인딩하여, T2I diffusion Model의 ouput domain에 embedding하는 것이다.
Reference
JiYeop Kim’s blog를 참고하여 작성하였습니다.