[Paper Reivew] Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Flow matching의 comprehensive and self-contained reviewd 입니다.

arXiv [Paper] [Github]
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan†, Bingyue Peng, Xiaobing Liu
Bytedance Inc
Dec 5, 2024
TL;DR
VAR을 Text-to-Image 로 확장하는 Bitwise Visual AR Modeling 방법론 Infinity 제안.
- Vocab size 를 \(2^{64}\)까지 scale up 하여 continuous VAE를 능가하는 성능 달성.
- Bitwise infinite-vocabulary classifier : index-wise가 아닌, bit-wise로 예측.
- Bitwise self-correction : Random flipping 이후 오류를 correction 하면서 robust하게.
이전포스팅 : VAR
1. Introduction
기존 저자들은 Coarse-to-fine 방식의 AR 모델인 next-scale prediction 방법론은 VAR을 제안했습니다. 하지만 저자들은 index-wise tokenizer는 vocab size 제한이 있을 때, 상당히 큰 quantization error가 발생하며 높은 해상도에서 fine-grained detail을 복원하는데 어려움을 겪는다고 합니다.
저자들은 bitwise modeling이라는 새로운 방법론을 제안합니다. 저자들의 bitwise modeling framework는 크게 3가지로 구성된다고 합니다.
bitwise visual tokenizer : tokenizer vocab size를 \(2^{64}\)까지 scale up하여 기존 discrete tokenizer의 성능을 훨씬 능가
bitwise infinite-vocabulary classifier : optimization, computation 문제 다루기 위해, index-wise classifier에서 bitwise classifier
bitwise self-correction: random하게 flipping bits, re-quantizing the residual features.
요약하자면 저자들의 기여는 다음과 같습니다.
- Infinity : AR model with Bitwise Modeling, bit wise로 vocab size를 키워 discrete tokenizer의 성능을 훨씬 향상.
- Scaling : Tokenizer, Transformer를 scaling하여, near-continuous tokenizer 성능을 달성함.
- 기존 Diffusion 방식보다 빠르면서, 이미지 퀄리티도 좋음.
2. Related Work
2.1. AutoRegressive Models
AR model은 discrete image tokenizer를 사용합니다. VQ-based 방법들은 이미지 패치를 index-wise token으로 바꾸기 위해 vector quantization을 하며, next token index를 예측하기 위해 decoder-only transformer를 사용합니다. 하지만 이런 방법들은 VQ-VAE의 내재적인 quantization error로 인해 scaling이 힘들다는 문제가 있습니다.
2.3. Scaling models
Scaling law란 AR 모델에서 model size, dataset size, compute 와 test set cross-entropy loss 사이 power-law 관계를 뜻합니다. 이는 효율적인 resource 배치에 도움을 주며, saturation 없이 계속 성능이 좋아진다는 주요 특징이 있습니다.
3. Infinity Architecture
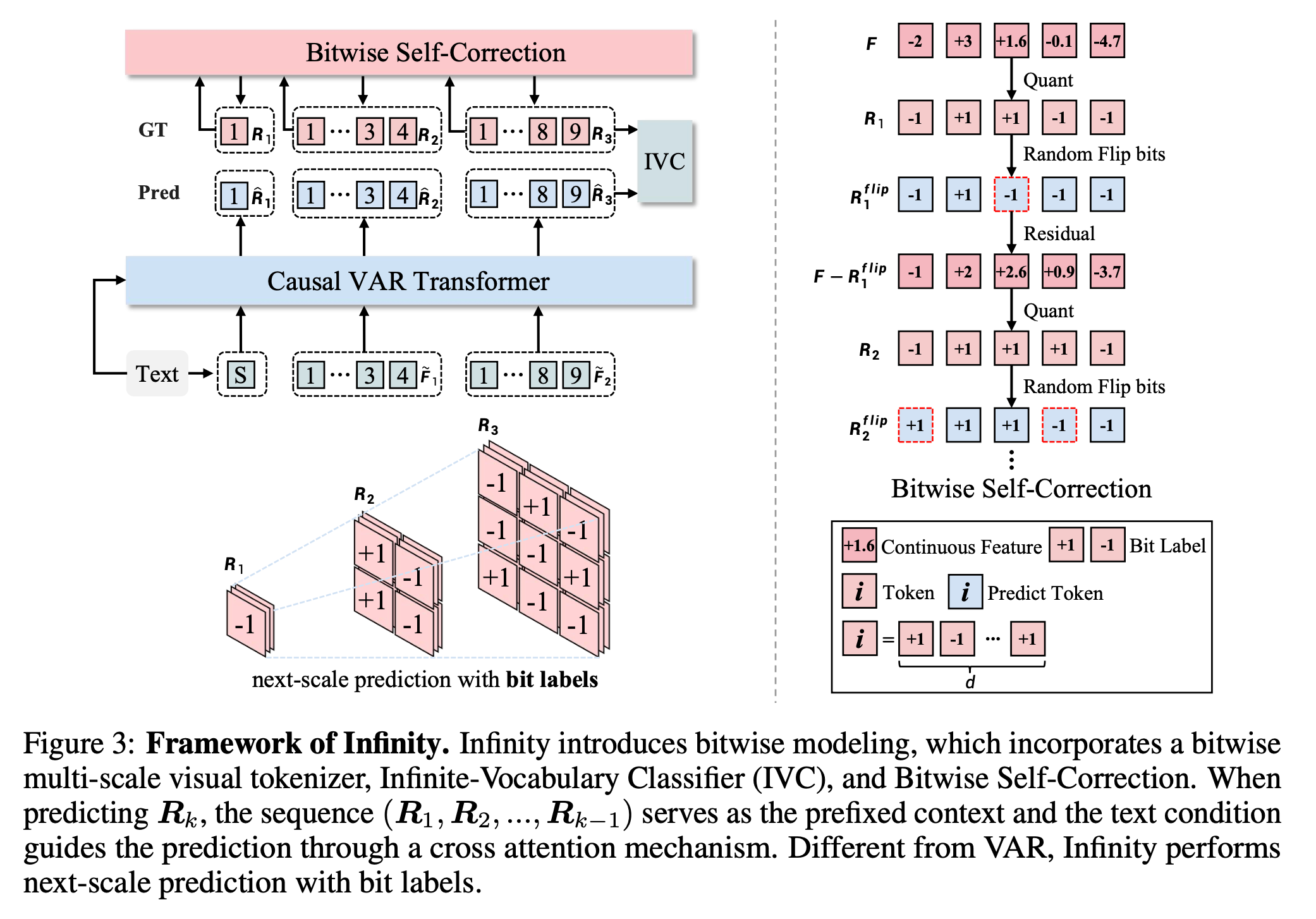
3.1. Visual AutoRegressive Modeling
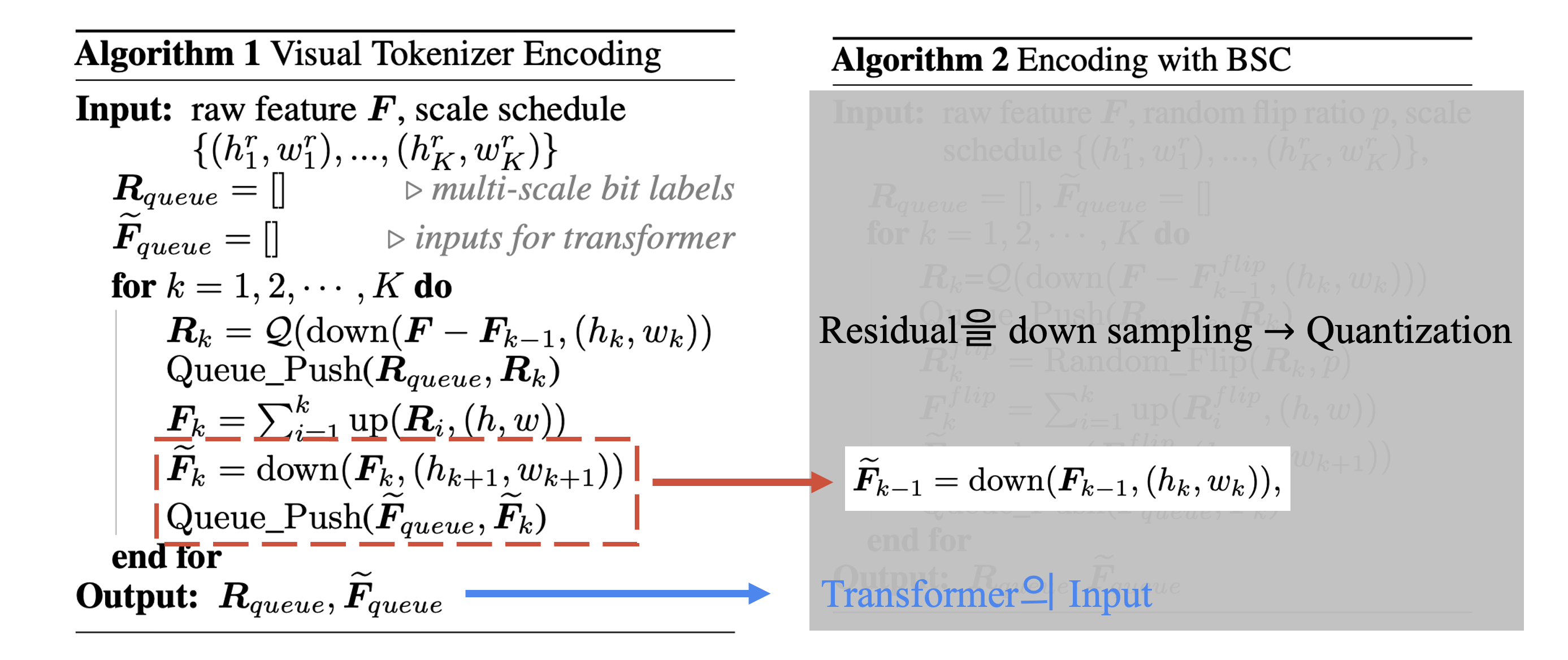
Infinity는 이미지 생성을 위해 visual tokenizer와 transformer를 이용합니다. visual tokenizer는 G.T. image를 feature map으로 encoding하며, 이를 quantize하여 \(K\) multi-scale residual map \((R_1, R_2, ..., R_k)\)를 얻습니다. \(F_K\)는 \(R_{\leq k}\)의 cumulative sum입니다.
\[F_k = \sum_{i=1}^k \text{up}(\mathbf{R}_i, (h, w))\]\(k\)-th scale, Transformer에서 input, output label \(R_k\)의 크기를 맞추기 위해 \(F_{k-1}\)를 downsampling 합니다. ( \(\tilde{F}_{k-1}\)와 \(R_k\)의 크기는 모두 \((h_k, w_k)\) )
\[\tilde{F}_{k-1} = \text{down}({F}_{k-1}, (h_k, w_k))\]이과정을 간단히 나타내면 다음과 같습니다.
3.2. Visual Tokenizer
Vocab size \(V_d\)를 키우는 것은 reconstruction, generation quality 향상에 큰 영향을 줍니다. 하지만 단순히 vocab size를 늘리면 상당한 memory consumption, computational cost… 등 문제가 있습니다.
이를 해결하기 위해 저자들은 bit-wise multi-scale residual quantizer를 제안합니다.
\[q_k = \mathcal{Q}(z_k) = \begin{cases} \text{sign}(z_k) & \text{if LFQ}, \\ \frac{1}{\sqrt{d}} \text{sign}\left(\frac{z_k}{|z_k|}\right) & \text{if BSQ}. \end{cases}\]하지만 LFQ 방식을 사용하기 위해서는 input \(z\)와 모든 코드북의 유사도를 계산해야 하는데, \(\mathcal O(2^d)\)의 복잡도로 불가능합니다. 따라서 저자들은 approximation formula를 제안한 BSQ 방식 \(\mathcal O(d)\)을 채택했다고 합니다.

3.3. Infinite-Vocabulary Classifier
기존 index-wise tokenizer는 \(V_d\)개의 class를 예측하는 classifer를 이용하여 index label를 바로 예측하는데, 이는 크게 huge computational costs와 fuzzy supervision 문제를 갖고 있다고 합니다. 또한 기존 방식은 0근처의 작은 perturbation으로도 index가 완전히 달라진다는 문제점이 있으며, 결과적으로 최적화 과정을 어렵게 합니다.
이를 해결하기 위해 저자들은 Infinite-Vocabulary Classifier (IVC) 를 제안합니다. \(V_d\)개의 class를 예측하는 classifier대신 \(d= log_2(V_d)\)개의 binary classifier만을 이용하면 되므로, memory를 상당히 줄일 수 있다고 합니다. (\(V_d = 2^{16}, h = 2048\)일 때 \(99.95 \%\)만큼 save.) 또한 0 근처의 값에서도 나머지 dimension에 대해서는 영향을 안 받으므로, 기존 방식에 비해 최적화가 쉽다고 합니다.
3.4. Bitwise Self-Correction
Teacher-forcing training 방식을 사용하면, train-test의 심각한 discrepancy가 생긴다고 합니다. 특히, mistake를 인식하고 교정하는 능력 없이, 단순히 각 scale의 feature만 refine하는 문제가 있다고 합니다. 이렇게 생긴 mistake는 inference에서 뒤쪽 scale로 전파되며, 생성 이미지 퀄리티를 떨어뜨린다고 합니다.
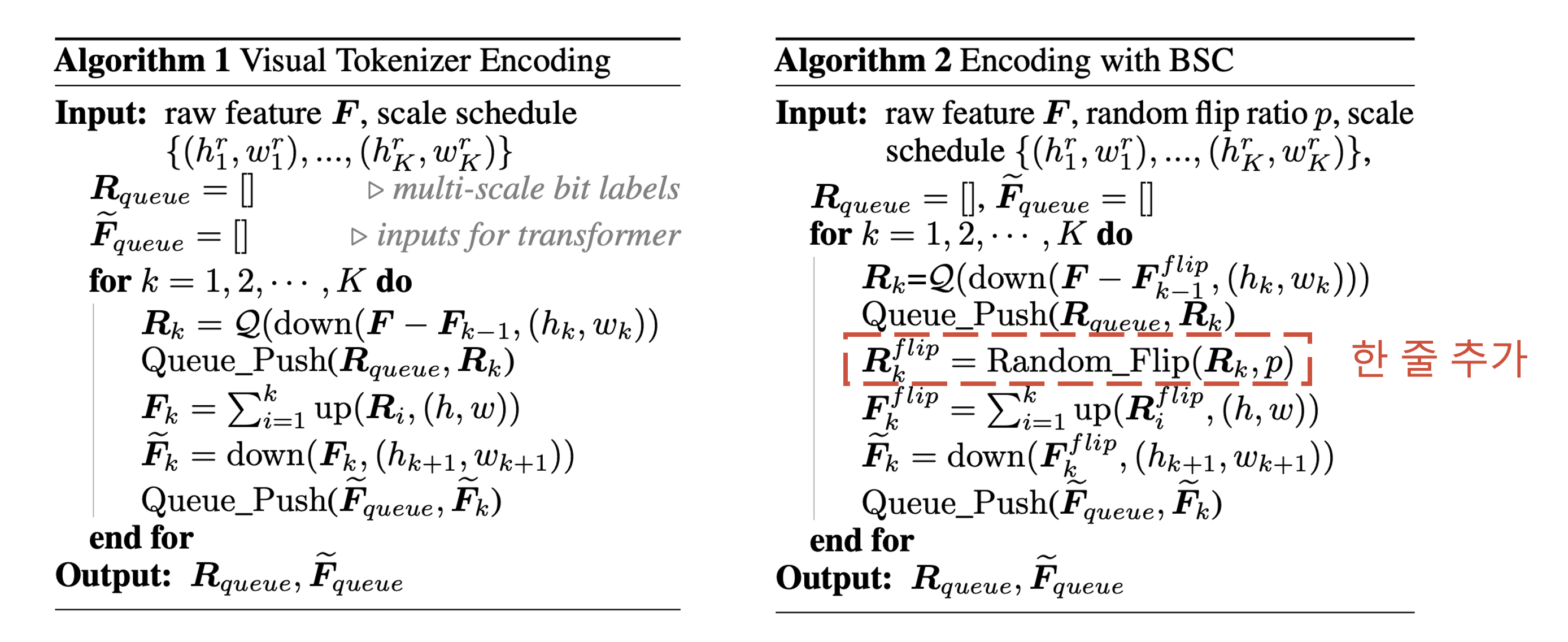
따라서 저자들은 Bitwise Self-Correction (BSC)를 제안합니다. \(R_k\)를 특정 확률로 flip하여 error가 포함된 \(R_k^{flip}\)을 이용해 기존 Algorithm 1대로 계산하면 됩니다. BSC를 통해 self-correction ability를 얻을 수 있었다고 합니다.
3.5. Dynamic Aspect Ratios and Position Encoding
VAR과 infinity가 다른 점 중 하나는, 다양한 Aspect Ratio (AR)에서 이미지 생성이 가능하다는 점입니다. 사실 여기에는 크게 두가지 문제가 있었다고 합니다.
- Scale schedule : 각 AR 에서 \(\{(h_1^r, w_1^r), ...., (h_K^r, w_K^r)\}\) 를 정하는 것은 쉽지 않았으나… 저자들이 몇가지 조합을 제시합니다.
- Resolution-aware positional encoding method : 여러 방법 중 저자들은 RoPE2d를 적용했다고 합니다.
4. Experiment
4.3.1. Qualitative Results
- Overall Results:


- Prompt-Following : Infinity는 prompt가 짧거나 상당히 길 때에도, 일관적으로 prompt를 잘 반영합니다.

- Text Rendering : 다양한 카테고리에 대해 text rendering이 가능하다고 합니다.

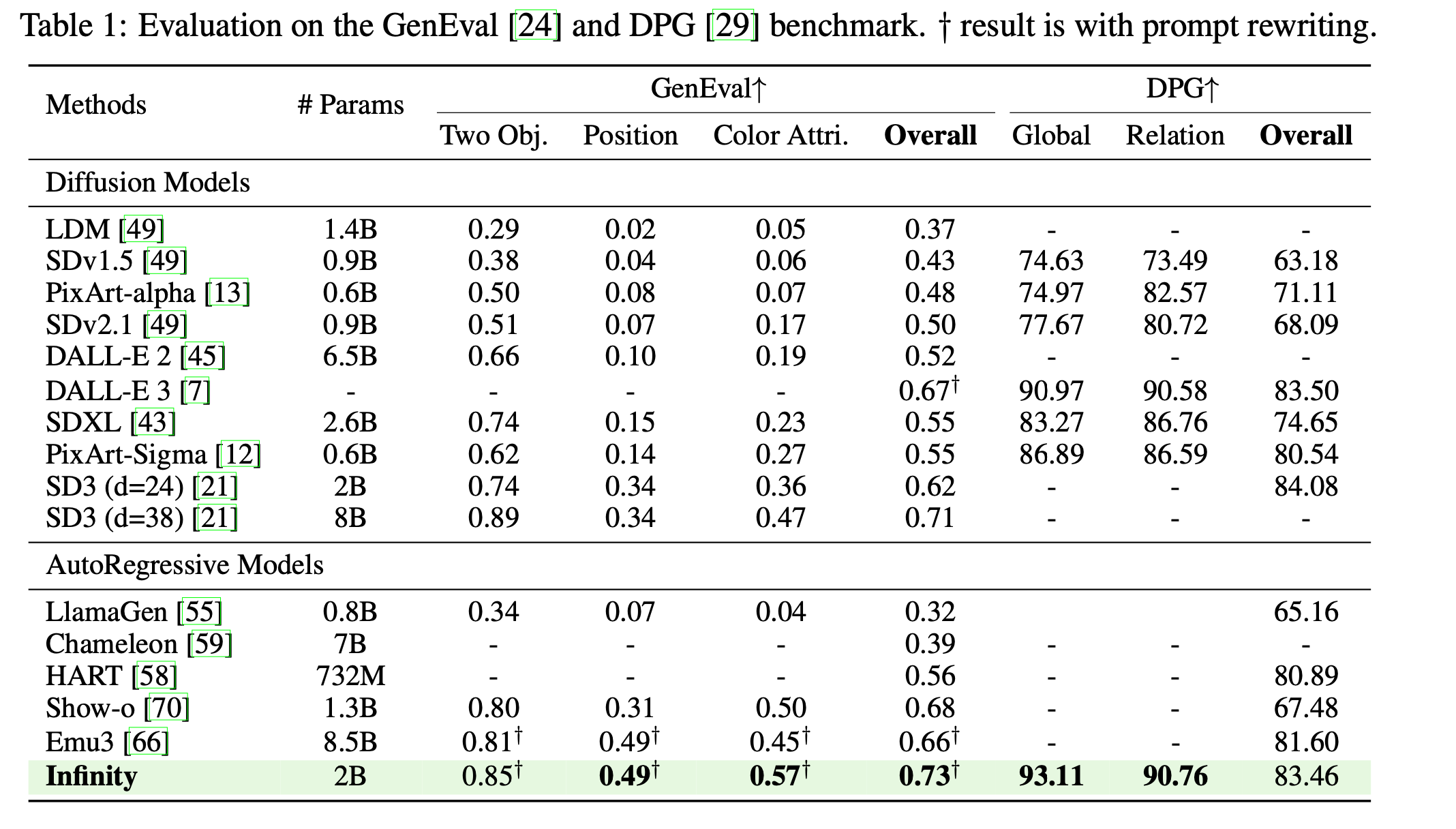
- Benchmark : GenEval, DPG benchmark에서도 좋은 성능을 보였습니다.
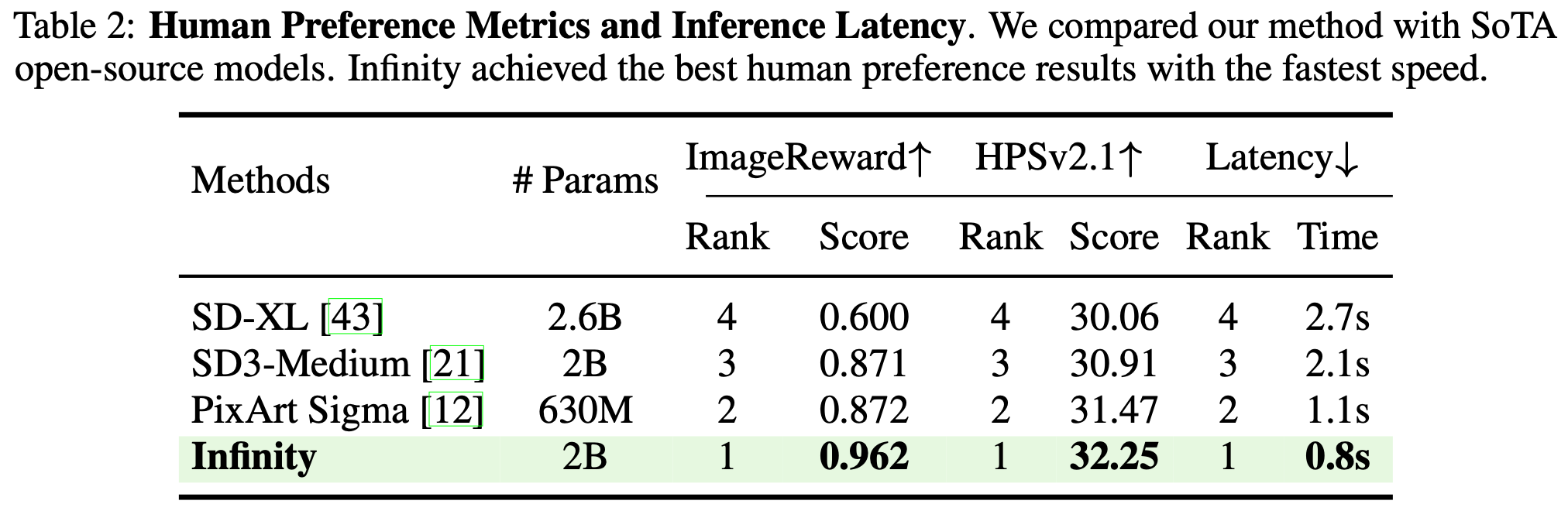
Human Preference Evaluation : Human Evaluation에서도 기존 모델을 능가하는 성능을 보여주었습니다.
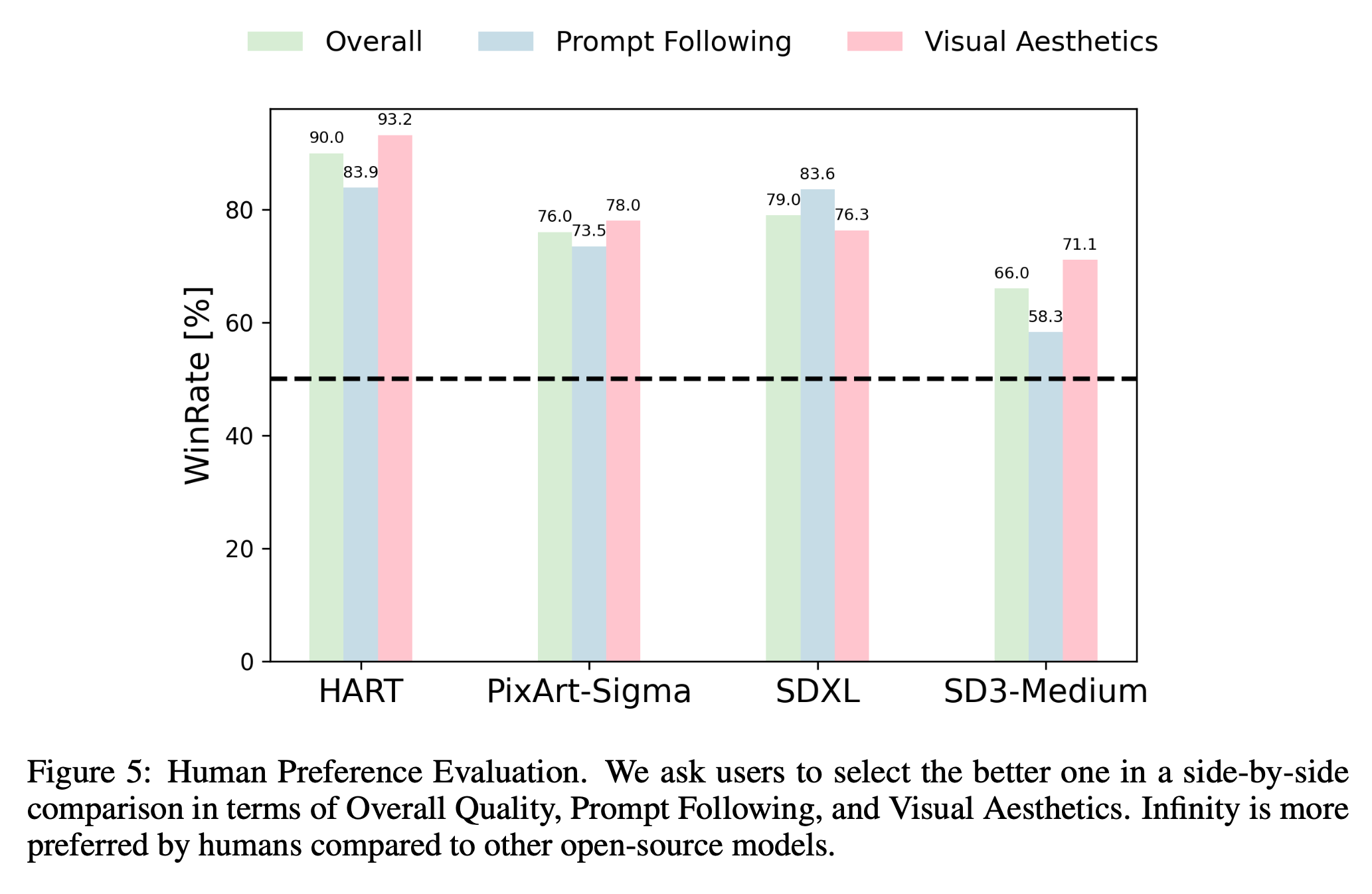
Inference Latency : Infinity의 장점은 AR 기반이다보니, Diffusion과 비교해 Inference 속도가 빠르다는 것입니다.
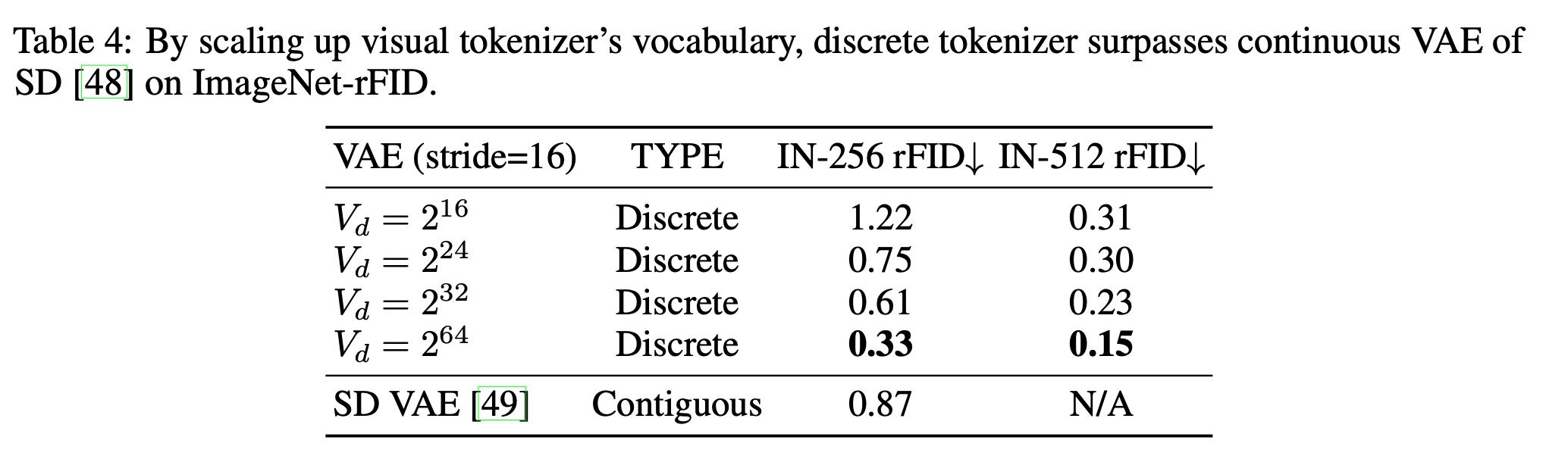
4.4. Scaling Visual Tokenizer’s Vocabulary
- Scaling Up the Vocabulary Benefits Reconstruction:
Vocab size제한이 있으면, discrete VQ-VAE는 항상 continuous VQ-VAE에 비해 성능이 떨어집니다. 하지만 저자들은 Vocab size를 scaling 하여 일관적으로 \(\text{rFID}\) 를 개선하며, SD의 continuous VAE 성능을 능가합니다.
- Infinite Vocabulary Classifier Benefits Generation :
IVC를 이용해 기존 index-wise classifier보다 성능을 높였다고 합니다.


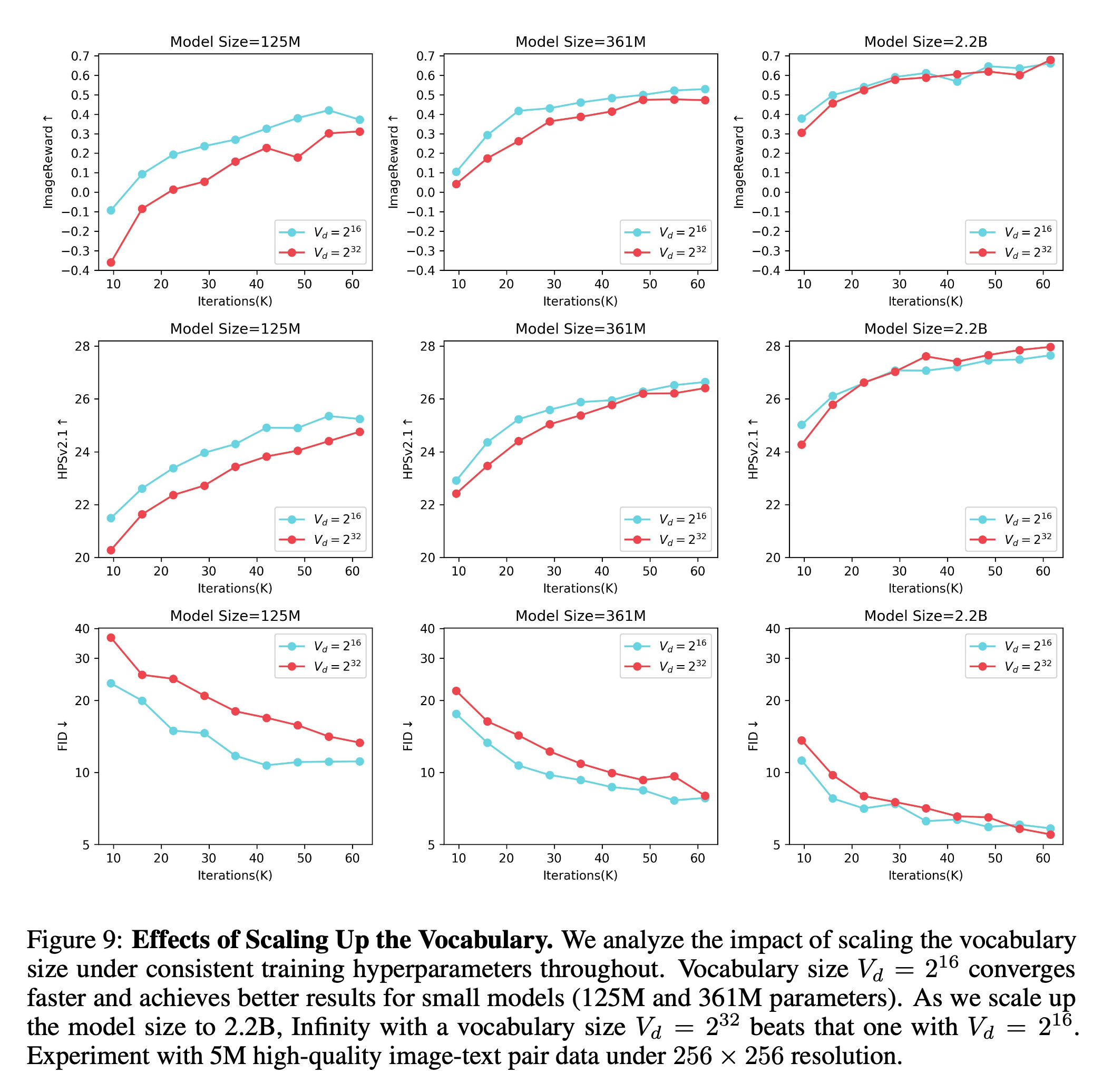
4.5. Scaling Bitwise AutoRegressive Modeling
- Scaling Up the Vocabulary Benefits Generation : 작은 모델에서는 \(2^{16}\)이 더 좋은 결과를, 큰 모델에서는 \(2^{32}\)이 더 좋은 결과를 보이는 것으로 보아, Vocab size는 transformer를 키우면서 같이 키워주어야 성능이 잘 나온다고 합니다.
- Scaling Up Transformer Benefits Generation : 저자들은 일관적으로 computational \(\text{FLOP}\)를 키웠을 때 일관적으로 Loss가 줄어드는 경향을 확인하였으며, (LLM과 비슷하게) 적절한 training을 통해 model size를 키우는 것이 성능을 올리는 좋은 방법이라고 합니다.
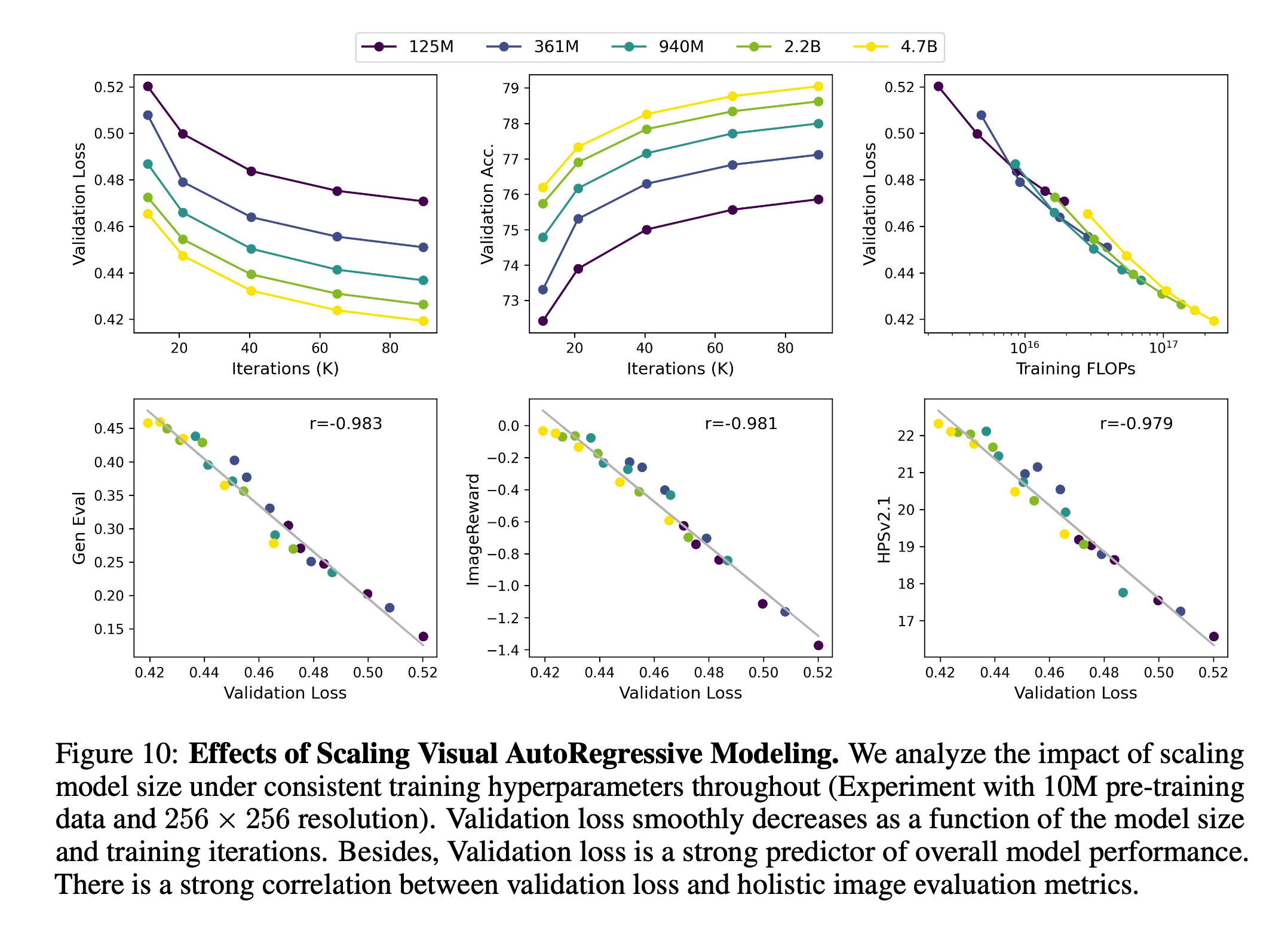

4.6. Bitwise Self-Correction
단순히 \(R_k\)를 random flipping하는 것은 성능 향상에 도움이 되지 않았다고 합니다. \(R_k^{flip}\)을 가지고 self-correction 메커니즘이 성능 개선에 많은 도움이 되었다고 합니다.

4.7. Ablation Studies
Optimal Strength for Bitwise Self-Correction : 실험 결과 30% 확률로 Random flipping 하는 것이 가장 성능이 좋았다고 합니다.
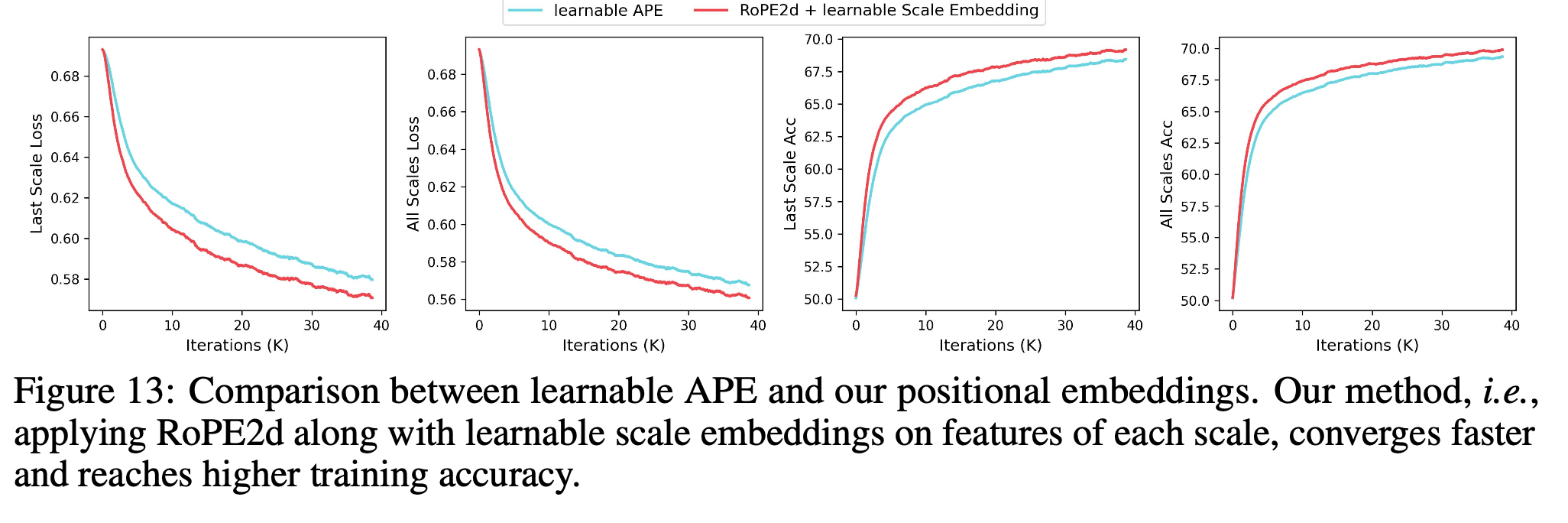
Positional Embedding : 저자들은 learnable APE와 RoPE + learnable scale embedding을 비교했습니다.
- Decoding : VAR 은 pyramid CFG on predicted logit 을 사용했지만, Infinity는 sampling에 더 robust하므로, ablation을 통해 최적의 decoding 구조를 탐색했습니다.