[Paper Reivew] Prompt-to-Prompt Image Editing with Cross Attention Control
Cross-attention layer를 활용해 원래 Object의 특징을 유지하면서 text-prompt로 이미지를 유연하게 editing하는 방법론을 제안합니다.

ICLR 2023 [Paper], [Page]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or
Google Research, Tel Aviv University
1 Aug 2024
TL;DR
Text-to-Image 모델에서 Cross-attention layer를 활용해 원래 Object의 특징을 유지하면서 text-prompt로 이미지를 유연하게 editing하는 방법론을 제안합니다.
1. Introduction

최근 대규모 텍스트-이미지(Large-scale Language-Image, LLI) 모델들(e.g. Imagen, DALL·E 2, Parti)은 매우 훌륭하지만…
이미지 특정 영역을 수정하는 방법은 없으며, text-prompt의 작은 변화는 완전히 다른 이미지를 생성하게 된다고 합니다.
기존 방법은 수정하고 싶은 영역을 masking하고, 해당 영역을 변경하는데 이는 masking된 영역의 구조적 정보를 무시하는 등 한계가 있다고 합니다.
본 논문에서 저자들은 Prompt-to-Prompt라는 직관적인 방법을 제안합니다. 저자들의 주장에 따르면 Cross-attention layer가 Image의 semantic과 text-prompt사이 관계를 제어하는 핵심이라고 합니다.
저자들의 핵심 아이디어는 diffusion process동안 cross-attention map을 Injection하여 어떤 pixel이 어떤 text token에 attend 해야 되는지 control하는 것입니다.
저자들의 방법은 학습이나, 추가적인 데이터가 전혀 필요하지 않으며, 단순히 text-prompt를 수정하는 간단한 방법으로 image editing을 할 수 있다고 합니다.
2. Related work
요점만 전달하자면…
기존 방법론은 text prompt에서 단어 하나만을 바꾸더라도 전체 이미지가 완전히 바뀌게 된다고 합니다. 이와 달리 저자들의 방법론은 spatial 정보를 잘 유지하면서 editing 가능!
3. Method
Text prompt \(\mathcal P\)로 생성한 이미지 \(\mathcal I\)라 할 때, 저자들의 목표를 정리하면 다음과 같습니다.
수정된 text prompt\(\mathcal P^*\) 만 이용해 , edited Image \(\mathcal I^*\)를 얻는 것!
Naïve한 접근법으로 random seed를 고정하는 것 만으로는 효과가 없었습니다.

저자들은 실험 과정에서 random seed에 더해, pixel과 text embedding의 interaction 이 이미지의 구조와 외형을 결정하는 핵심이라는 것을 관찰하였습니다. cross-attention layer에서 발생하는 interaction을 제어함으로써, Prompt-to-Prompt image editing 능력을 제시합니다.
특히 cross-attention map을 이미지 \(\mathcal I\)에 Injecting 함으로써, original 이미지 구조를 유지하면서 이미지 편집이 가능하다고 합니다.
3.1. Cross-attention in text-conditioned Diffusion Models
Diffusion model에서 cross-attention이 어떻게 사용되는지 간단한 리뷰입니다.
먼저 각 diffusion step \(t\)에서는 noisy latent \(z_t\)와 text embedding \(\psi(\mathcal P)\)로부터 noise \(\epsilon\)을 예측합니다. (마지막 step까지 진행되면 \(\mathcal I = z_0\)) 가장 중요하게는 text, image 두 modality간 interaction은 Cross-attention map에서 발생하며, 각 text token 마다 spatial attention map을 만듭니다.

\[M = \text{Softmax}(\frac {QK^T} {\sqrt d})\]Cross-Attention의 작동 원리
- Query, Key, Value: 크로스 어텐션은 입력 이미지와 텍스트 간의 관계를 모델링하기 위해 사용됩니다.
- Query(Q): 이미지 feature에서 추출되며, 이미지의 각 부분이 텍스트의 어떤 정보를 사용할지를 결정합니다.
- Key(K), Value(V): 텍스트 임베딩에서 추출되며, 각각 텍스트의 의미와 텍스트가 이미지에 미치는 영향을 표현합니다.
직관적으로 이해하자면, cross-attetion \(MV\)는 \(V\)에 대한 weighted average이며, 이때 weight는 \(Q, K\)간 유사성으로 정해집니다.
3.2 Controlling the Cross-attention
Cross-attention이 중요하다는 것은 알겠지만 어떻게 Control 할 수 있을까요?
먼저 저자들의 핵심 관찰로 돌아가봅시다. 
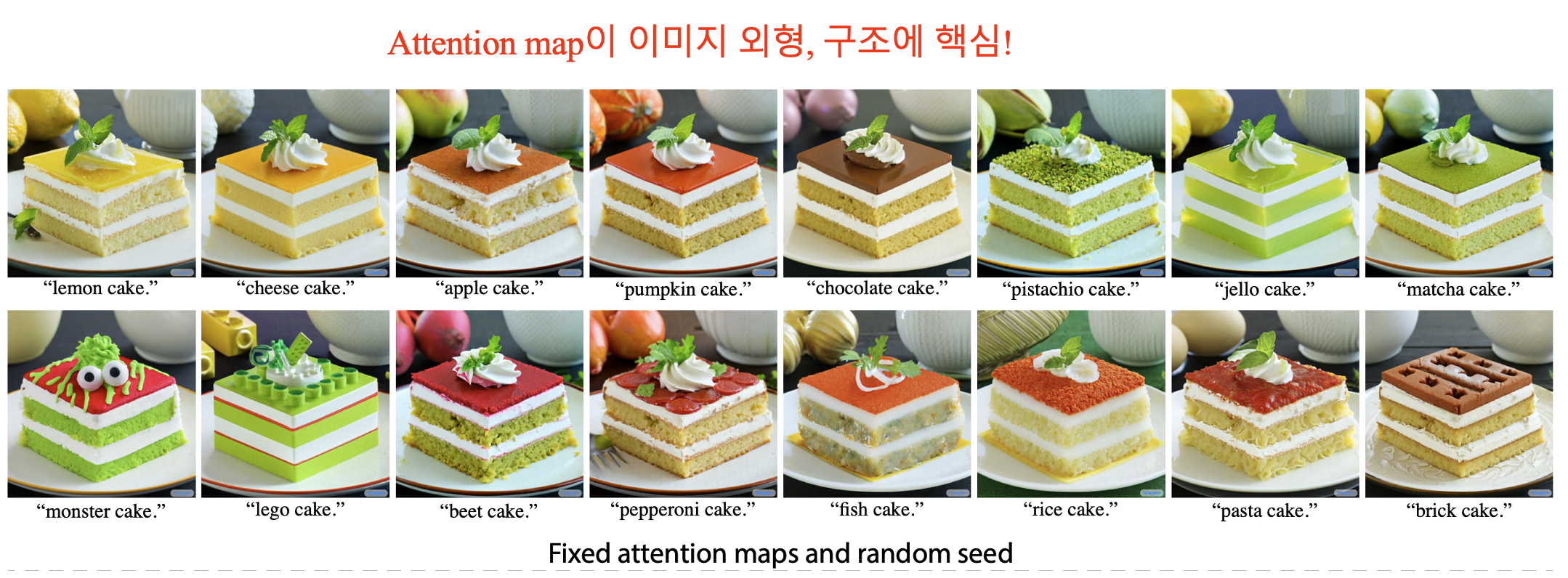
위에서 볼 수 있듯이, Spatial layout, geometry는 cross-attention map에 의존합니다. (특히 그 단어와 관련된 부분에 더 attend 하는 것을 볼 수 있습니다) 특히나 아래 그림에서 볼 수 있듯이 diffusion step의 초기부터 전체적인 image structure이 정해집니다.
따라서 ‘text prompt \(\mathcal P\)로 얻은 Attention map \(M\)을 \(\mathcal P^*\)로 생성할 때 injection하겠다!’ 가 저자들의 핵심 아이디어 입니다. 그렇게 된다면 text-prompt에 따라 이미지를 생성하면서 동시에, input image의 structure를 보존할 수 있게 되는 것이죠.
알고리즘을 살펴 봅시다.
\(DM(z_t, \mathcal P, t, s)\)를 \(t\) step에서의 diffusion process라 하면, output은 noisy image \(z_{t-1}\), attention map \(M_t\)입니다.
\(Edit(M_t, M_t^*, t)\)는 \(t's\) attention map(\(M_t\))을 받아, \(M_t^*\)를 수정하는 general edit function입니다.

이미 생성된 이미지 \(\mathcal I\)를 입력으로 정의할 수 있으나, 알고리즘의 과정은 동일하며, 특히 \(z_{t-1}\), \(z_t^*\)는 같은 batch에서 실행 될 수 있으므로, only one step만 손해를 본다고 합니다.
정리하자면,
- 텍스트 프롬프트를 바꿔가면서 diffusion process를 통해 attention map \(M_t\), \(M_t^*\)를 얻고,
- 이를 적절히 수정하여, \(\hat M_t\)를 얻습니다.
- \(\hat M_t\)를 이용해 diffusion process로 \(z_{t-1}^*\)를 계산하면 됩니다.
그렇다면… attention map은 어떻게 수정할까요?
Word Swap

Word swap은 특정 단어를 다른 단어로 바꾸어 이미지를 수정하는 방법입니다. 이 task의 main challenge는 original 부분을 보존하면서 특정 content만 바꾸는 것입니다.
단순히 attention map을 injection하는 것은 over constrain일 수 있기 때문에, 다음과 같이 초기 step에서만 injection을 하는 방법(softer attention constrain)을 사용했습니다.
\[Edit(M_t, M_t^*, t) := \begin{cases} M_t^* & \text{if } t < \tau, \\ M_t & \text{otherwise.} \end{cases}\]이를 통해 새 프롬프트에 맞는 기하학적 자유도를 보장하면서 원본 구성은 유지할 수 있었다고 합니다.

Adding a New Phrase

사용자가 새로운 token을 추가하는 경우, common detail을 보존하기 위해, 공통된 단어에만 attention injection을 했다고 합니다. 이를 위해 Alignment function \(A\)를 사용해 \(\mathcal{P}^*\)의 token index를 \(\mathcal{P}\)의 대응 토큰으로 mapping 합니다.
\[(Edit(M_t, M_t^*, t))_{i,j} := \begin{cases} (M_t^*)_{i,j} & \text{if } A(j) = None, \\ (M_t)_{i,A(j)} & \text{otherwise.} \end{cases}\]Attention Re–weighting

사용자가 프롬프트의 특정 토큰이 이미지에 미치는 영향을 강화하거나 약화하고자 할 때(예: “a fluffy red ball”에서 “fluffy”의 영향을 조정), 이를 세밀하게 조작할 방법이 필요합니다.
이는 특정 토큰(“fluffy”)의 attention map을 scaling 하는 방식으로 가능하다고 합니다.
\[(Edit(M_t, M_t^*, t))_{i,j} := \begin{cases} c \cdot (M_t)_{i,j} & \text{if } j = j^*, \\ (M_t)_{i,j} & \text{otherwise.} \end{cases}\]4. Application
Text-Only Localized Editing
User가 제공하는 마스크 없이 prompt만으로 localized editing을 할 수 있습니다.
Fig2, fig5에서와 같이, 공간적 layout, 기하학적 구조, semantic을 유지하면서 배경도 잘 보존하는 것을 확인할 수 있습니다.
Texture뿐만 아니라 structural 수정도 가능합니다. fig6를 보면 “bicycle” → “car”
단어를 완전히 바꾸는 것뿐만 아니라, 새로운 단어를 추가하는 것도 가능합니다.

Global editing
Global한 수정을 하면서도, 이미지 구성을 유지하는 것이 목표입니다. 이미지의 전체적인 부분에 영향을 미치면서도, object의 위치와 정체성 같은 정보는 유지해야 하는 것입니다.

Fader Control using Attention Re-weighting
프롬프트만으로 원하는 이미지를 완벽히 제어하기 어려운 경우도 존재합니다. 예를 들어, snowy mountain에서 눈의 양을 어떻게 조절할 수 있을까요?
저자들은 특정 단어의 attention을 Re-scaling을 통해 이를 해결했다고 합니다.

Real Image Editing
실제 이미지를 편집하려면, 입력 이미지가 diffusion model에 주어졌을 때, 해당 이미지를 생성하는 initial noise를 찾아야 합니다. 이는 Inversion으로 알려져 있습니다.
DDIM 기반의 deterministic한 방법을 사용해, diffusion process를 역으로 진행했다고 합니다.

real image에서도 어느정도 잘 동작하지만, 많은 경우 inversion이 제대로 이루어지지 않는 경우가 존재했다고 합니다. 저자들은 이런 현상은 distortion-editability tradeoff 문제 때문일 수 있다고 합니다.

이를 해결하기 위해 저자들은 수정되지 않은 원빈 이미지의 영역을 마스크를 통해 복원했다고 합니다. 이 mask는 attention map에서 자동으로 추출되며, 사용자의 개입이 필요 없습니다.

5. Conclusions
Text-to-Image Diffusion 모델에서 Cross-attention Layer는 텍스트 프롬프트와 생성된 이미지의 공간 레이아웃을 연결하는 중요한 역할을 함.
텍스트 프롬프트의 조작으로 생성 이미지의 속성을 직관적이고 유연하게 제어할 수 있음.
[1]: Flow straight and fast: Learning to generate and transfer data with rectified flow
X. Liu, C. Gong, Q. Liu. arXiv preprint arXiv:2209.03003. 2022.