[Paper Reivew] Return of Unconditional Generation: A Self-supervised Representation Generation Method
Self-supervised Encoder를 이용해 representation을 modeling하고, 이를 condition으로 이용하는 Image generator를 사용하는 RCG 제안.

NeurIPS 2024. Oral [Page][github]
Tianhong Li, Dina Katabi, Kaiming He
MIT CASIL
1 Nov 2024
TL;DR
Self-supervised Encoder(e.g. MoCo V3)를 이용해 representation을 modeling하고, 이를 condition으로 이용하는 Image generator를 사용하는 RCG 제안.
Unconditional image generation quality를 class-conditional과 견줄만큼 높였습니다.
1.Introduction
Unconditional generation은 human annotation(e.g. class label, text description) 없이 데이터 분포를 모델링하는 문제로, 생성 모델 분야에서 오랫동안 연구된 중요한 주제입니다. 그러나 최근 연구들에 따르면, conditional 정보를 주고 학습하는 방식에 비해 생성 품질이 현저히 떨어지는 한계가 있었습니다.
이 문제의 주요 원인은 human annotation이 제공하는 rich semantic 정보의 부족으로, 모델이 데이터 분포의 다양한 모드와 의미를 명시적으로 학습하지 못했기 때문이라고 저자들은 분석합니다. 이에 대해 저자들은 Self-Supervised Learning (SSL) 을 통해 학습된 representation이 human annotation 없이도 의미적 정보를 충분히 포착할 수 있음을 활용해, 생성 품질을 크게 개선할 수 있다고 주장합니다.
저자들이 제안한 framework Representation-Conditioned Generation (RCG) 다음과 같은 방식으로 동작합니다.
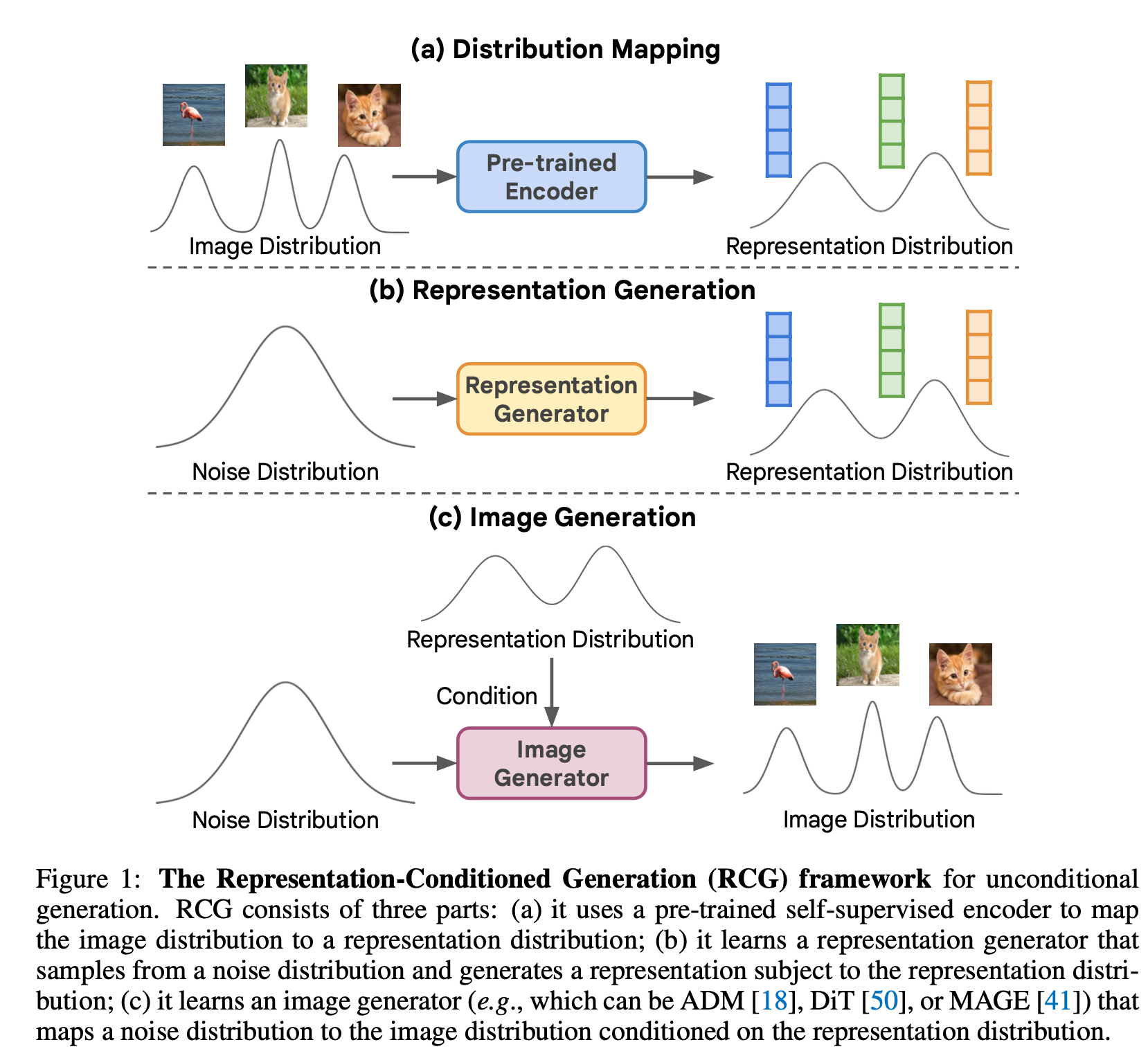
- a. Pre-trained SSL Encoder: 이미지를 차원이 낮은 semantic representation으로 mapping
- b. Representation Generator :
- representation space에서 conditioning 없이 generator를 학습 (낮은 차원에서는 condition 없이도 data 분포를 잘 학습)
- Noise로부터 representation distribution 얻음.
- c. Image Generator: Representation distribution을 condition으로 이미지를 생성
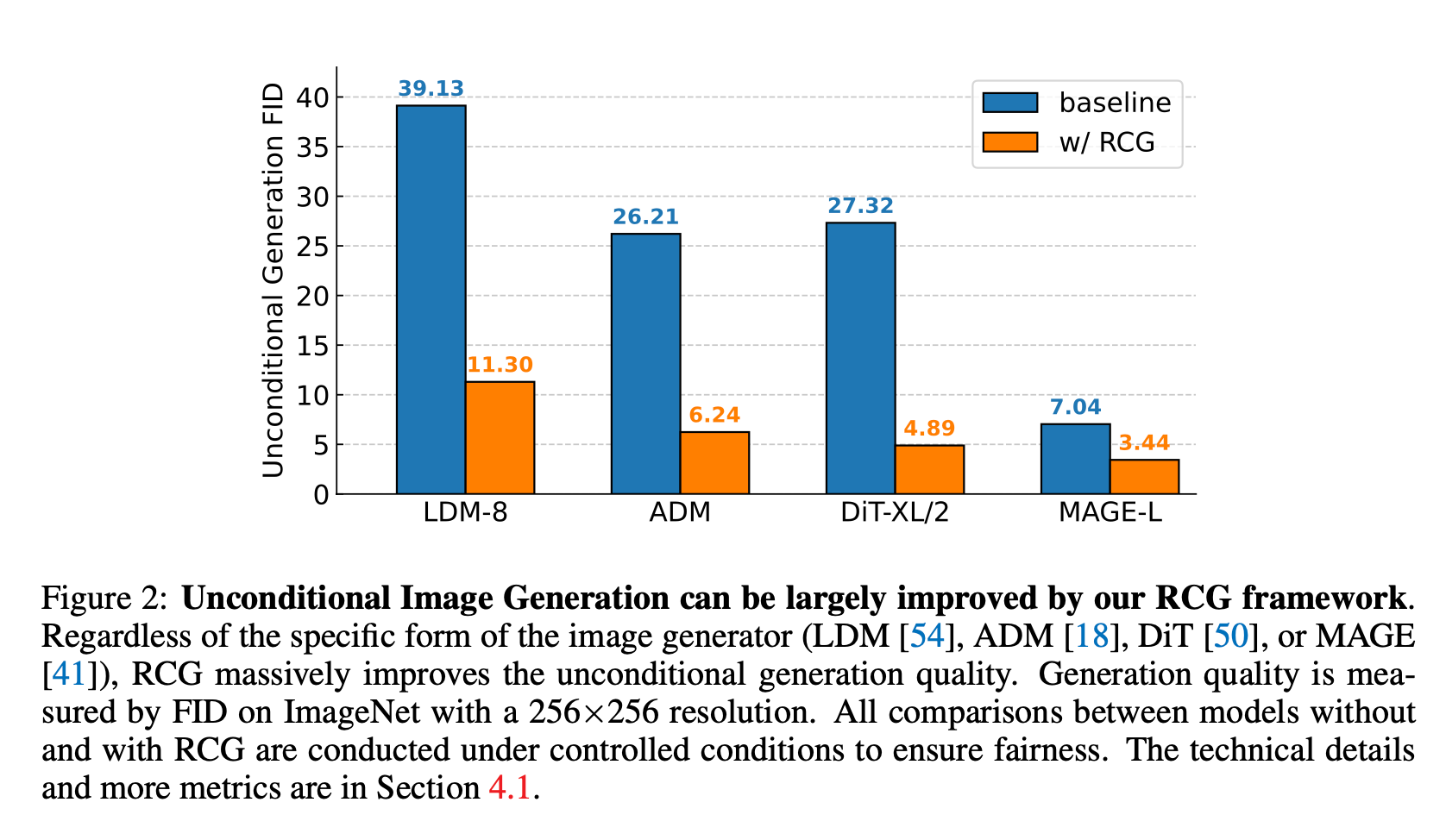
RCG는 개념적으로 간단하고 유연하며, 조건 없는 생성에서 매우 효과적이라고 합니다. 실제로 위 그림에서 볼 수 있듯이, RCG는 image generator에 관계없이 unconditional 생성 품질을 크게 향상시킵니다. 이는 현재의 생성 모델이 수동 라벨에 의존하는 정도를 크게 줄인다는 것을 의미합니다.
정리하자면…
- Unconditional generation이라는 어려운 문제를 representation 생성 + image 생성 두 문제로 나눠서 풀었다.
- Self-Supervised Learning (SSL) encoder의 representation이 human annotation 보다 더 많은 정보를 담고 있다. (class condition 보다 성능이 잘 나왔으므로)
2. Related Work
Unconditional Generation
이 논문 이전에도 conditional과 unconditional의 차이를 줄이려는 연구가 있었는데, 주로 representation space에서 clustering하고, 이를 class label 처럼 사용하려 시도 했습니다. 하지만 이는 dataset이 clustering이 가능하며, class label과 비슷한 clustering 수를 가져야 함을 가정하는 한계가 있습니다.
Representations for Image Generation
Representation을 활용하려는 기존 연구들이 있었습니다.
- DALL-E 2 : text-prompt를 image embedding 으로 바꾸고, 이 embedding을 condtion으로 이미지 생성.
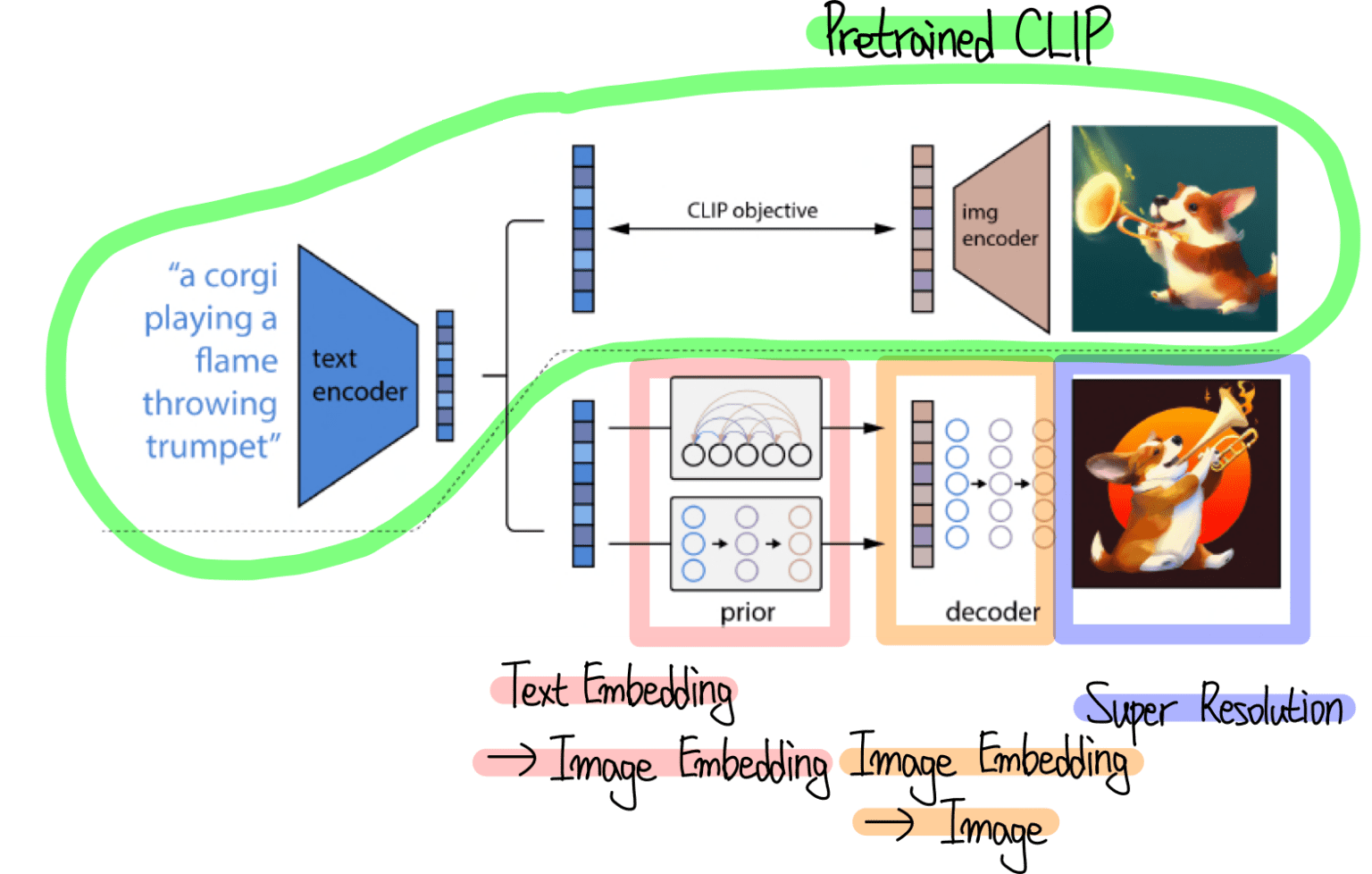 출처, https://ffighting.net/deep-learning-paper-review/diffusion-model/dalle2/
출처, https://ffighting.net/deep-learning-paper-review/diffusion-model/dalle2/
- DiffAE : Diffusion model을 decoder로 사용해, decordable image representation을 학습하려는 시도가 있었지만, SSL 방식(MoCo, DINO 등)에 비해 semantic한 표현 능력이 부족했습니다.
3. Method
높은 차원의 image distribution을 직접 모델링 하는 것은 매우 어려운 task로 RCG에서는 2개의 쉬운 sub-task로 나누어 풀었습니다.
- 저차원 representation distribution 을 modeling.
- representation distribution 를 conditon으로 하는 image distribution 을 modeling.
3.1. The RCG Framework
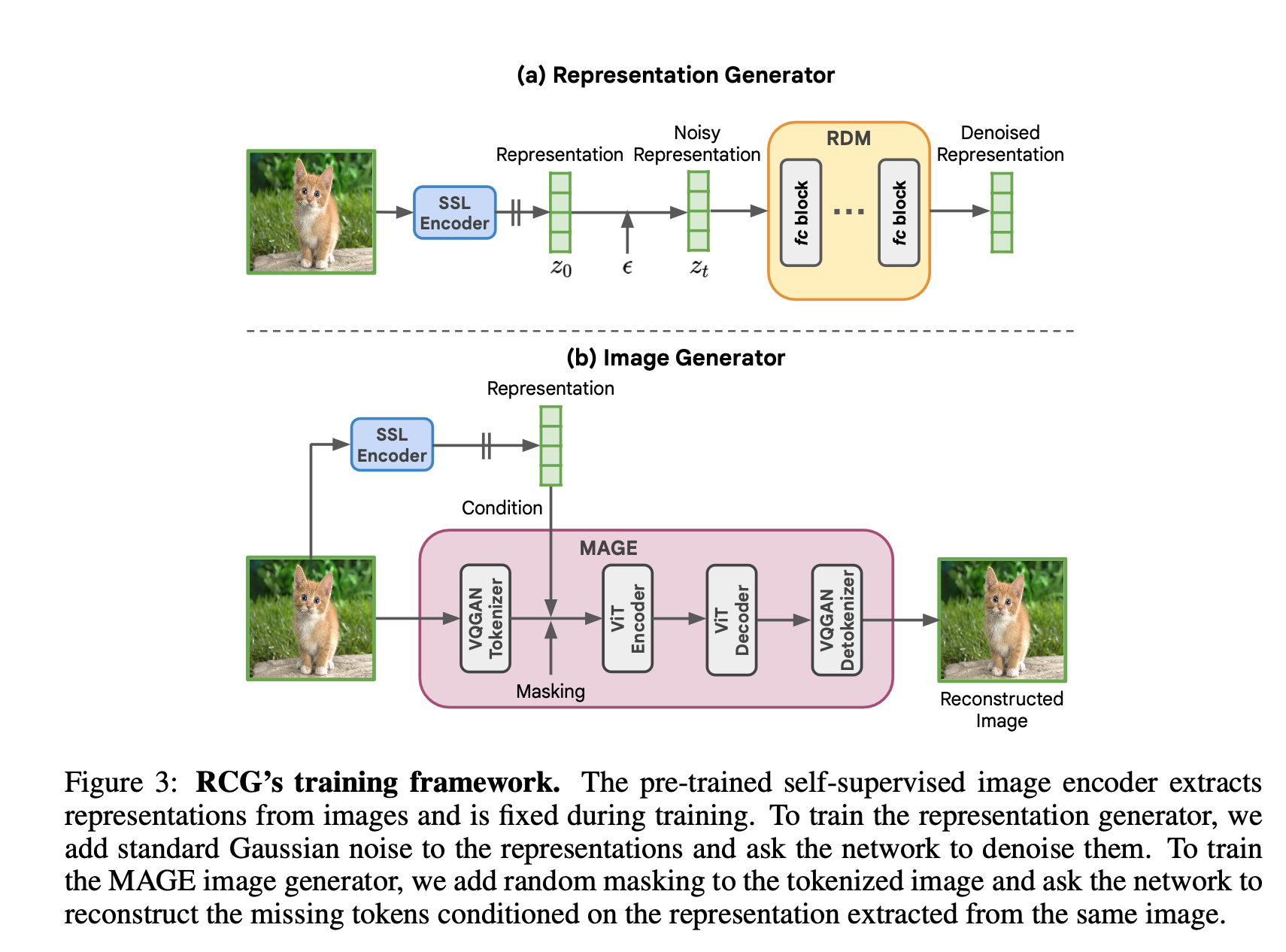
앞에서 말한 것처럼 RCG는 3개의 파트로 구성되어 있습니다. 1) Distribution Mapping (Pre-trained SSL Encoder), 2) Representation Generator, 3) Image Generator
1) Distribution Mapping
RCG에서는 MoCo v3와 같이, ImageNet에서 pre-trained된 Image encoder를 사용합니다. Representation distribution 결과는 다음과 같습니다.
- Unconditional generator가 학습할 수 있을 정도로 매우 단순.
- 고차원 semantic한 정보를 담고 있어, 이미지 생성에 중요한 guide 제공.
2) Representation Generator
위에서 얻은 representaion을 학습하고, 생성하는 Representation Diffusion Model (RDM)을 제안합니다. 구조는 FC layer와 residual로 구성된 간단하고, 가벼운 네트워크 입니다.
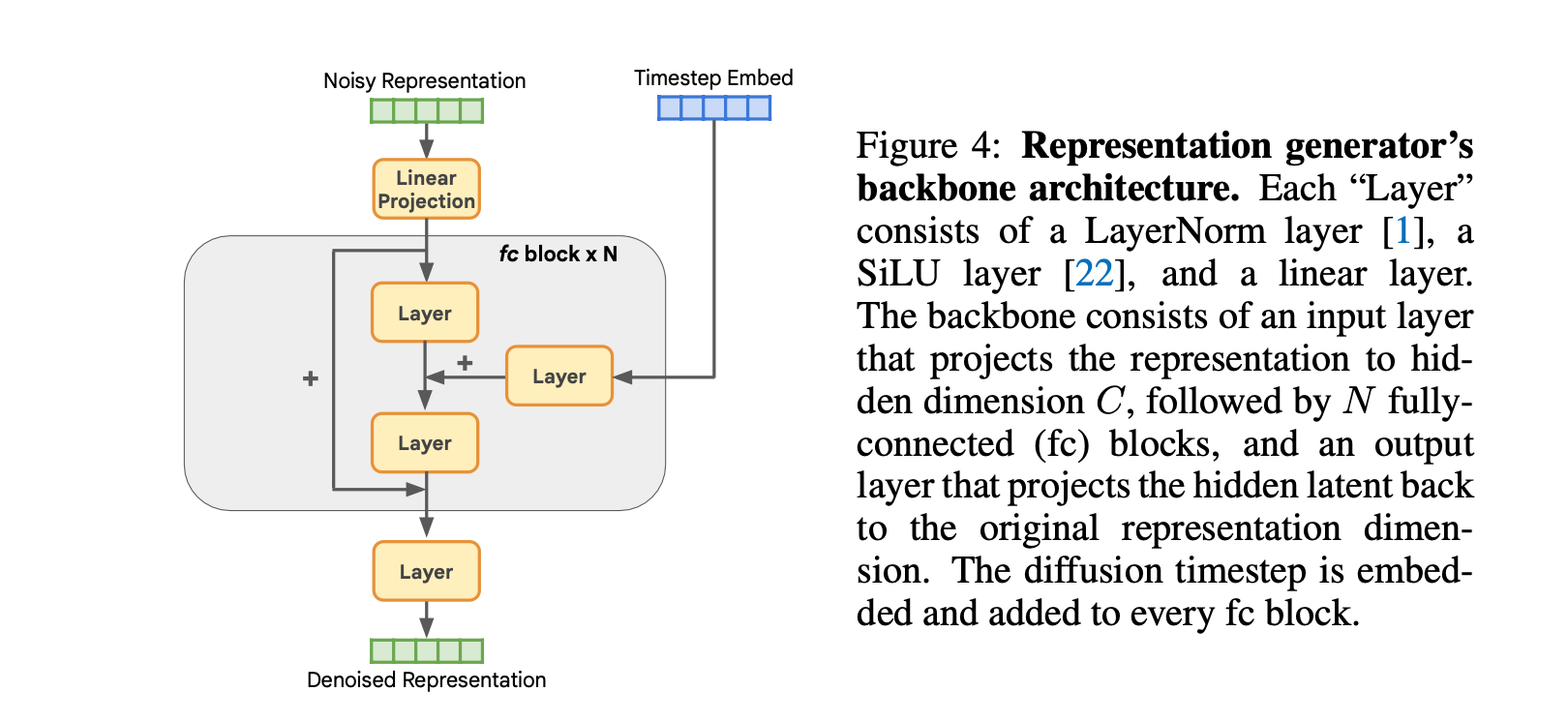
3) Image Generator
Image generato는 아무런 Conditional image generation model을 사용할 수 있으며, 저자들은 MAGE를 사용했다고 합니다.
MAGE는 masked 된 이미지를 recon 하도록 학습되고, Inference시 전체 maksing하고 이미지 생성하는 model
3.2. Extensions
Enabling Guidance in Unconditional Generation
CFG같이 class label을 이용해 생성 과정을 guide 하는 데에도, Representation conditioning을 이용할 수 있다고 합니다.
Simple Extension to Class-conditional Generation
RDM의 FC block에 class embedding을 추가하기만 하면, class-conditional 이미지 생성이 가능하다고 합니다. 이런 간단한 extension은 image generator의 추가적인 학습 없이 특정 Class image를 생성할 수 있도록 합니다.
4. Experiments
저자들은 ImageNet 256×256 dataset을 이용해 실험했으며, FID, IS Metric으로 생성 품질을 비교합니다.
4.1. Observations
RCG significantly improves the unconditional generation performance of current generative models
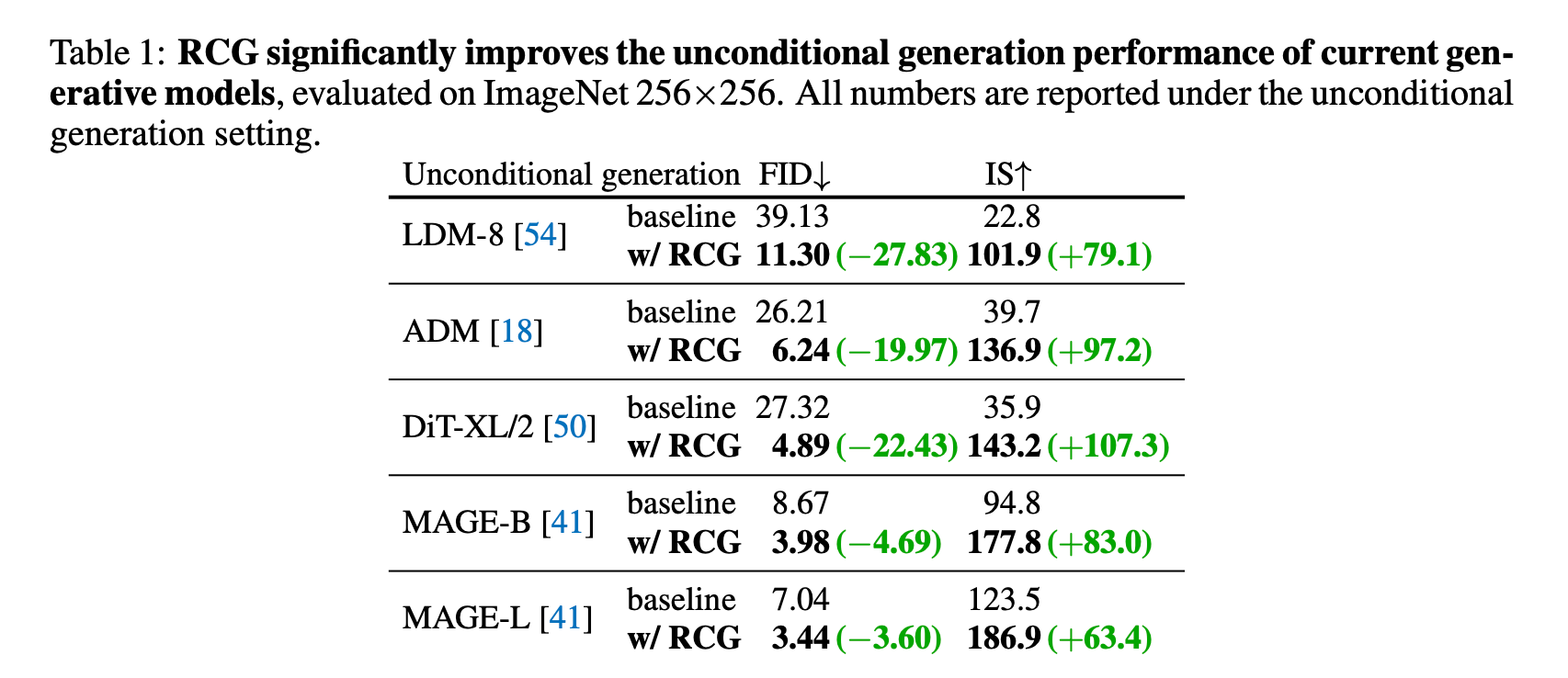
이 논문의 핵심인 것 같습니다. RCG를 이용하면 기존 방법론에서 FID를 아주 크게 개선할 수 있음을 보였습니다.
RCG largely improves the state-of-the-art in unconditional image generation

RCG는 unconditional image generation에서 SOTA를 크게 개선했습니다.
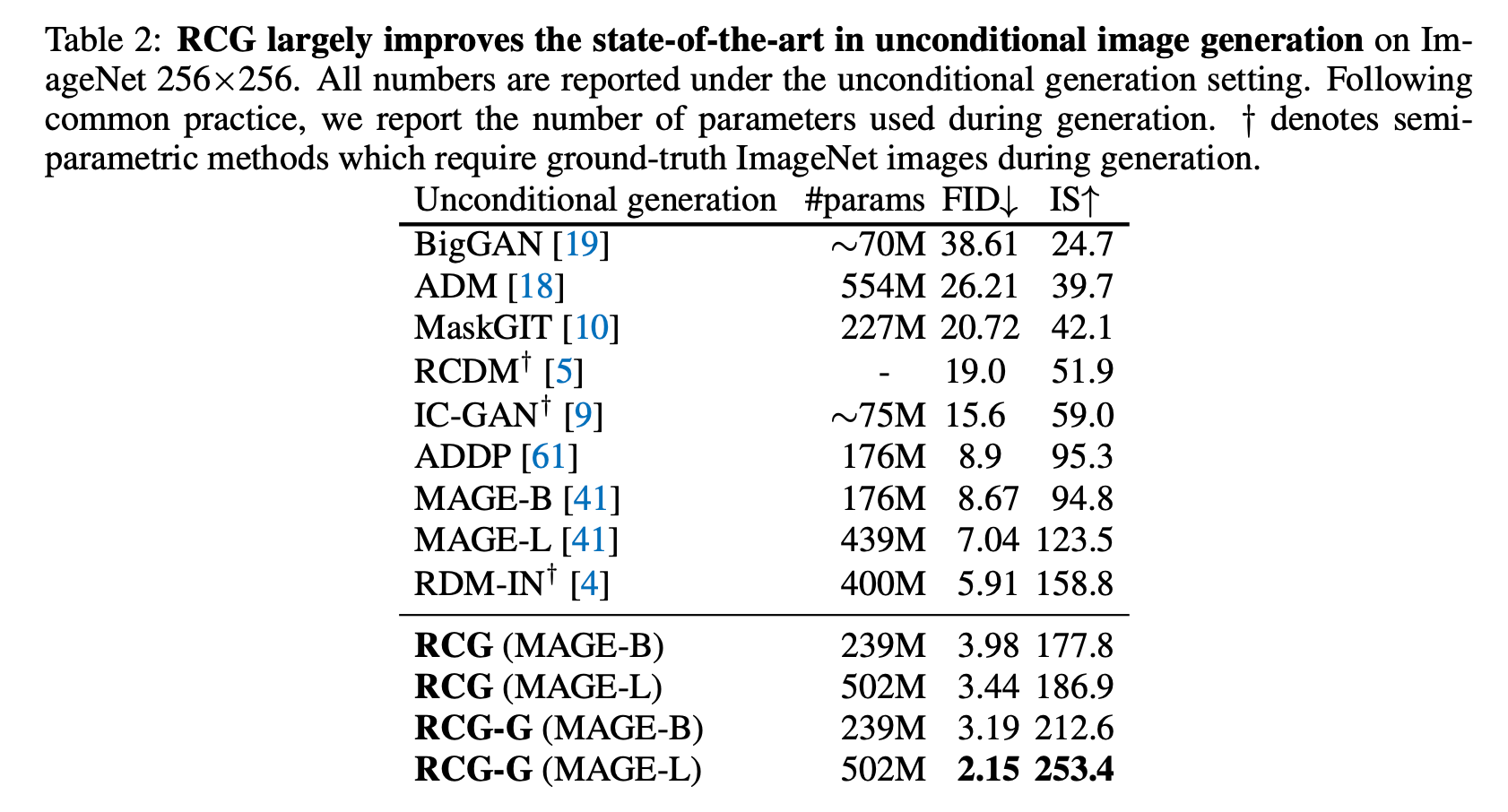
이러한 결과는 가이드 버전의 RCG(RCG-G)를 통해 더욱 향상되며, RCG-G는 FID 2.15와 Inception Score 253.4를 기록하여 기존 방법들을 크게 능가합니다.
RCG’s unconditional generation performance rivals leading methods in class-conditional image generation
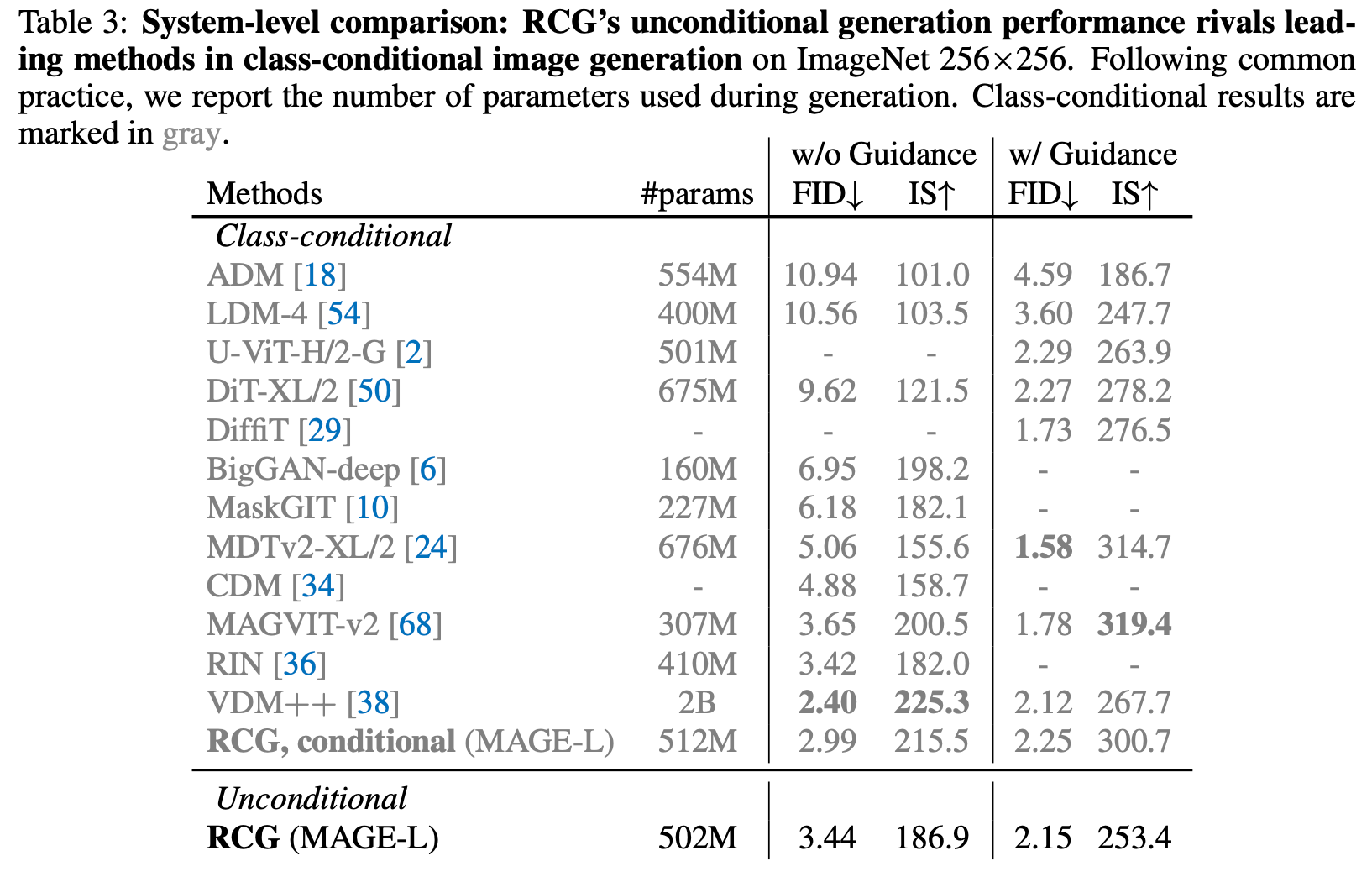
심지어 RCG는 class-conditional 이미지 생성과도 견줄 만합니다.
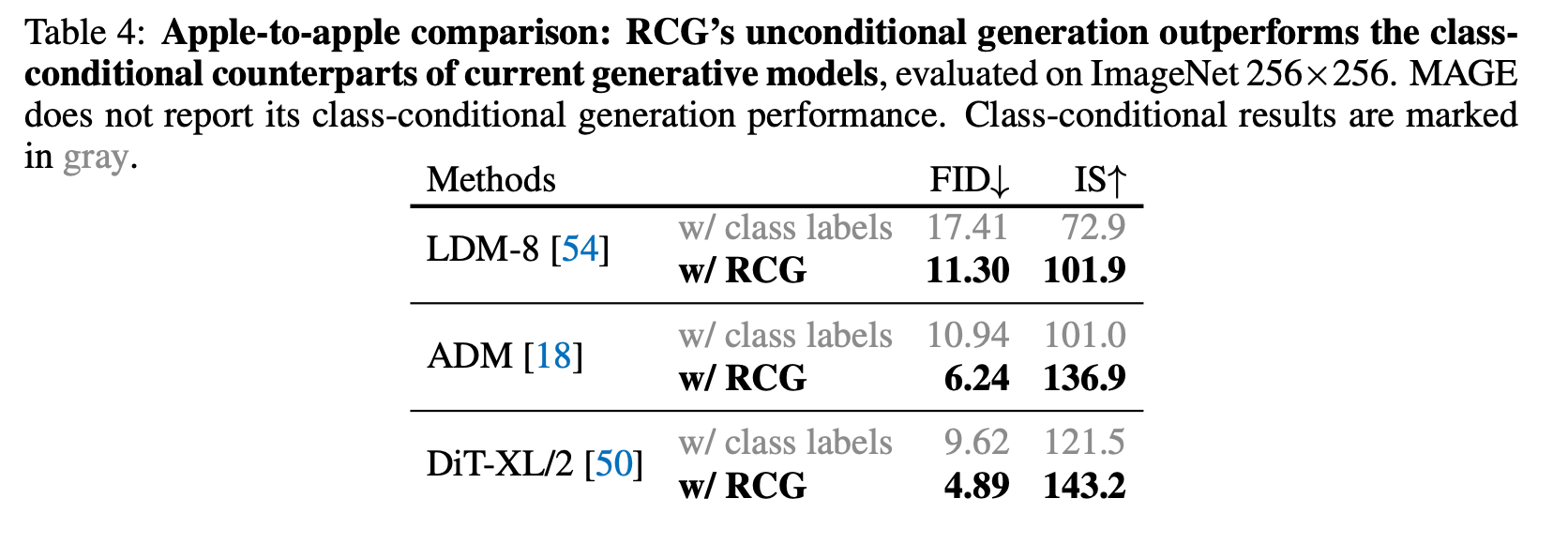
놀랍게도, RCG를 적용했을 때 이러한 생성 모델들은 class-conditional 버전보다 일관되게 더 나은 성능을 보였습니다. SSL의 representations이 class label보다 생성 과정을 더 효과적으로 안내할 수 있음을 보여줍니다.
또한 RCG의 장점은 새로운 데이터가 추가되었을 때, 상대적으로 가벼운 representaion generator만 학습하면 되므로 효율적이라고 합니다.
4.2. Qualitative Insights
저자들은 RCG의 high-level semantic 정보는 Representation Generator에서 비롯된다고 합니다. Representation distribution을 modeling하고, semantic 정보를 가진 representation을 생성하는데, 이를 condition으로 사용함으로써, 복잡한 data 분포가 간단한 conditional 분포로 분해된다고 합니다. 이를 통해 image generator의 작업을 크게 단순화하여 높은 품질의 이미지를 생성할 수 있습니다.

RCG가 동일한 참조 이미지에서 추출된 표현을 기반으로 다양한 세부사항을 가진 이미지를 생성할 수 있음을 보여줍니다.

생성된 이미지의 의미가 점진적으로 두 이미지 사이를 전환하며, RCG의 representation interpolation 능력을 강조합니다.
5. Discussion
- Unconditional image 생성에서 SSL representation을 사용하여 conditional 생성 수준의 성능에 도달.
- Human annotation 없이 대규모 데이터셋을 활용할 수 있는 가능성 제시.