[Paper Reivew] RealFill: Reference-Driven Generation for Authentic Image Completion
RealFill은 참조 이미지의 내용을 바탕으로 목표 이미지의 누락된 영역을 충실하게 복원하는 Authentic Image Completion 방법입니다.

arXiv 2024. [Paper] [Project Page]
Luming Tang, Nataniel Ruiz, Qinghao Chu, Yuanzhen Li, Aleksander Hołyński, David E. Jacobs, Bharath Hariharan, Yael Pritch, Neal Wadhwa, Kfir Aberman, Michael Rubinstein
Cornell University, Google Research, Snap Research
July 2024
Abstract
참조 기반 이미지 복원은 참조 이미지의 정보를 활용하여 목표 이미지에서 누락된 영역을 채우는 작업입니다. 이는 다양한 시점, 조명, 스타일의 차이를 극복해야 하며, 목표는 “있어야 하는 특징”을 복원하는 것입니다. 이를 위해, 저자들은 간단하면서도 효과적인 접근법인 RealFill을 제안합니다. RealFill은 사전 학습된 inpainting diffusion 모델을 참조 이미지와 목표 이미지로 fine tune한 후, 이 조정된 모델을 사용하여 목표 이미지의 누락된 영역을 채웁니다. RealFill은 참조 이미지와 목표 이미지 간의 시점, 초점 흐림, 조명, 이미지 스타일, 피사체 자세의 차이가 클 때에도 참조 이미지의 내용에 충실한 고품질 복원을 생성할 수 있습니다.
TL;DR
RealFill은 참조 이미지의 내용을 바탕으로 목표 이미지의 누락된 영역을 충실하게 복원하는 Authentic Image Completion 방법입니다. RealFill은 T2I inpainting diffusion 모델을 1~5장의 reference와 target 이미지에 대해 finetuning하여 시점, 조명, 스타일 차이가 큰 경우에도 사실적인 복원을 제공합니다.
1. Introduction

RealFill은 reference-driven generation을 사용하여 누락된 이미지 부분을 복원하는 새로운 Image completion 방법론 RealFill을 제안합니다.
Authentic Image Completion 문제 정의 : 주어진 target 이미지(1장)와 reference 이미지(~5장)를 바탕으로, target 이미지에서 누락된 부분을 실제로 ‘있어야만 하는’(‘있을 것 같은’이 아니라) 콘텐츠로 채우는 것이 목표입니다. 이때 reference이미와 target이미지는 view-point, 조명 조건, 카메라 설정, 이미지 스타일, 심지어 움직이는 물체까지 큰 차이가 있을 수 있습니다.
기존 방식의 문제 :
- Geometry-based pipelines. 대응점 매칭, 심도 추정, 3D 변환 등을 사용하여 이미지를 보완하지만, 복잡한 장면 구조나 동적 객체가 있는 경우 잘 동작하지 않는다고 합니다.
- Diffusions. 텍스트 프로픔트 설명에 의존해 이미지를 생성하지만, 참조 이미지에서 추출된 실제 장면 정보를 반영하지 못하는 문제가 있다고 합니다. 특히 정교한 디테일을 생성하는데 어려움을 겪습니다.
RealFill 제안 : 저자들은 Authentic Image Completion를 효과적으로 해결하기 위해 Reference-driven image completion framework(RealFill)을 제안합니다. Pretraining된 inpainting diffusion 모델을 reference 이미지를 이용해 finetuning하여 missing(or masked) region을 효과적으로 생성하도록 사용합니다.
저자들은 이 과정에서 Correspondence-Based Seed Selection을 도입하여, 참조 이미지와 일치하지 않는 저품질의 샘플을 자동으로 제거합니다. 이를 통해 사용자의 개입을 줄이고, 최종 출력물의 품질을 보장할 수 있었다고 합니다. RealFill의 가장 큰 장점은 참조 이미지와 목표 이미지 간에 큰 차이가 있어도, 참조 이미지의 세부 정보를 충실히 반영하여 누락된 부분을 자연스럽게 복원할 수 있다는 것입니다.
간단히 요약하자면,
- 저자들은 Authentic Image Completion문제를 정의합니다. 몇 장의 reference 이미지로 target 이미지의 missing 부분을 ‘그 곳에 있어야만 하는 것’들로 채우는 과정.
- 이를 위해 RealFill 제안합니다. Pretrained inpainting diffusion 모델을 fine tune하는 과정으로 학습하는데, 이때 Correspondence-Based Seed Selection로 낮은 품질은 자동으로 제거됩니다.
- 이런 in/out-painting 문제의 Benchmark로 RealBench를 사용할 것을 제안.
2. Related Work
2.1. Adapting Pretrained Diffusion Models
최근에는 사전 학습된 text-to-image (T2I) diffusion models을 다양한 작업에 맞춰 finetuning하는 연구들이 활발히 진행되고 있습니다. 특히 Personalization methods는 몇 장의 이미지만을 사용하여 텍스트 기반의 임의 객체나 스타일을 생성할 수 있도록 T2I 모델 또는 text embedding을 finetuning하는 방식을 제안합니다.
또 다른 접근 방식은 이미지 편집이나 controllable generation을 위해 새로운 conditioning signals을 추가하는 방식이 있습니다.
2.2. Image Completion
Image Completion task는 이미지의 누락된 부분을 자연스럽게 채우는 것을 목표로 하며, inpainting과 outpainting 작업으로 나뉩니다. 고전적인 예전 연구들은 주로 기하학 기반의 대응 방식을 사용했으나, 최근에는 learning-based 방식을 사용하는 추세입니다.
특히, 최근에는 좋은 성능을 보여주는 Pretrained T2I의 prior를 이용하려는 연구가 진행되고 있지만, 이들은 주로 text prompt에만 의존해 결과물을 생성하므로 실제 장면의 구조나 세부 사항을 복원하는 데 한계가 있다고 합니다.
2.3. Reference-Based Image Inpainting
Reference-based inpainting 방법은 참조 이미지를 사용해 목표 이미지를 복원하는 방식입니다. 이 접근 방식은 depth estimation, image warping, image harmonization 등 여러 모듈로 이루어진 복잡한 파이프라인을 사용합니다. 하지만 이러한 모듈의 예측 오류가 누적되면서 결과물의 품질이 떨어지는 경우가 많습니다.
Paint-by-Example은 참조 이미지와 목표 이미지를 함께 condition으로 사용하는 Latent Diffusion Model(LDM)을 제안했지만, 참조 이미지가 1장일 때, CLIP embedding을 이용해 conditioning하므로 고차원적인 정보만을 이용할 수 있는 한계가 있었다고 합니다.
이에 비해 RealFill은 여러 참조 이미지를 사용해 다양한 차이점(뷰포인트, 조명, 스타일)을 극복하며, 더 자연스럽고 사실적인 이미지를 생성합니다 .
3. Method
3.1. Reference-Based Image Completion
다시 반복하자면 저자들의 목표는 몇 장의 reference 이미지를 이용해 target 이미지에서 inpainting/outpainting을 하는 것이다.
In essence, we want to achieve authentic image completion, where we generate what “should have been there” instead of what “could have been there”. -논문 인용
3.2. Preliminaries
Diffusion Models. 계속 반복되지만…. 어려우니 한번 더 정리하겠습니다. 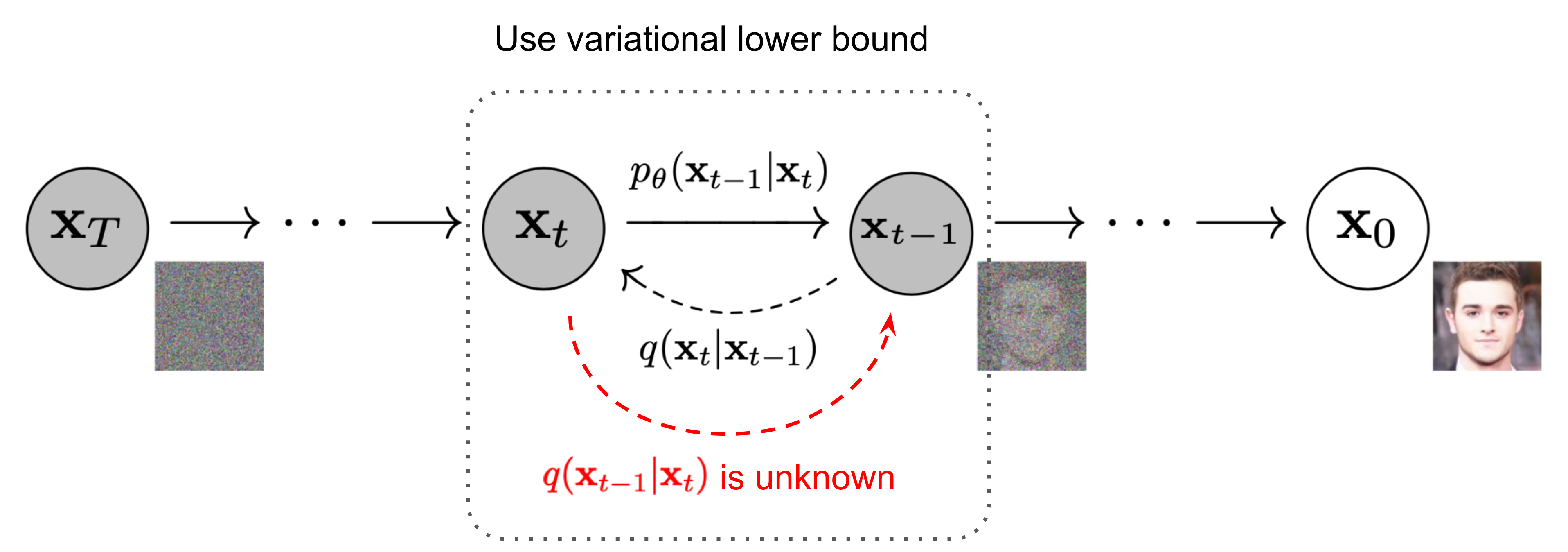
- Forward Process : 훈련 과정에서 가우시안 노이즈가 데이터 포인트 \(x_0\)에 순차적으로 추가되어 noisy 데이터 \(x_t\)를 얻습니다. 이때 다음과 같은 수식으로 나타낼 수 있습니다. \(x_t = \sqrt{\alpha_t} x_0 + \sqrt{1 - \alpha_t} \varepsilon\)
Forward Process => 미리 정해진대로 이미지에 노이즈를 더해나가는 과정.
- Reverse Process : Forward Process에서 더해진 노이즈를 제거하는 과정입니다. 이 때 이미지가 제거된 이미지를 예측할 수 있지만, DDPM에서 노이즈를 직접 예측하는 것이 더 효과적이라고 합니다. 이때 노이즈를 수식적으로 계산할 수 없으니, 학습을 통해 예측하는 모델을 Diffusion 모델이라고 합니다. Loss function은 다음과 같습니다. \(L = \mathbb{E}_{x,t,\varepsilon} \left[\| \varepsilon_\theta (x_t, t, c) - \varepsilon \|_2^2 \right]\)
Reverse Process => 더해진 노이즈를 학습을 통해 배우고 예측하는 과정.
DreamBooth.1 T2I diffusion model을 이용해 특정 물체를 생성하는 방법을 제안한 연구입니다. 핵심만 전달하자면, 몇 장의 reference 이미지를 이용해 특정 대상과 identifier를 연관짓도록 finetuning하는 방식입니다. 이후 연구에서 메모리 효율성을 위해 LoRA와 결합하는 것이 가능하다는 것이 알려졌습니다.
3.3. Problem Setup
RealFill 모델은 최대 5개의 참조 이미지 \(X_{\text{ref}} = \{ I_k^{\text{ref}} \}_{k=1}^{n}\)와 target 이미지 \(I_{\text{tgt}} \in \mathbb{R}^{H \times W \times 3}\), Binary mask \(M_{\text{tgt}} \in \{ 0, 1 \}^{H \times W}\)를 입력으로 받습니다.
생성된 이미지의 픽셀은 \(M_{\text{tgt}} = 0\)인 영역(마스킹 되지 않은 영역)은 원본 이미지 \(I_{\text{tgt}}\)와 최대한 비슷해야 하며, \(M_{\text{tgt}} = 1\)인 영역(마스킹 된 영역)은 reference 이미지 \(X_{\text{ref}}\)의 특징을 충실하게 담아내야 합니다.
Input :
- 최대 5개의 reference 이미지 \(X_{\text{ref}}\)
- 1개의 target 이미지 \(I_{\text{tgt}}\)
- Mask \(M_{\text{tgt}}\) (1이 마스킹 된다는 뜻)
3.4. RealFill
Training. 저자들은 \(X_{\text{ref}}\)와 \(I_{\text{tgt}}\)를 이용해 SOTA 성능의 (LoRA를 연결한) T2I diffusion inpainting 모델(Stable Diffusion v2 inpainting model)을 finetuning합니다.
\(L = \mathbb{E}_{x,t,\varepsilon,m} \left[\| \varepsilon_\theta(x_t, t, p, m, (1 - m) \odot x) - \varepsilon \|_2^2 \right]\)
masking되지 않은 영역(\(m = 0\))만 Loss 계산.
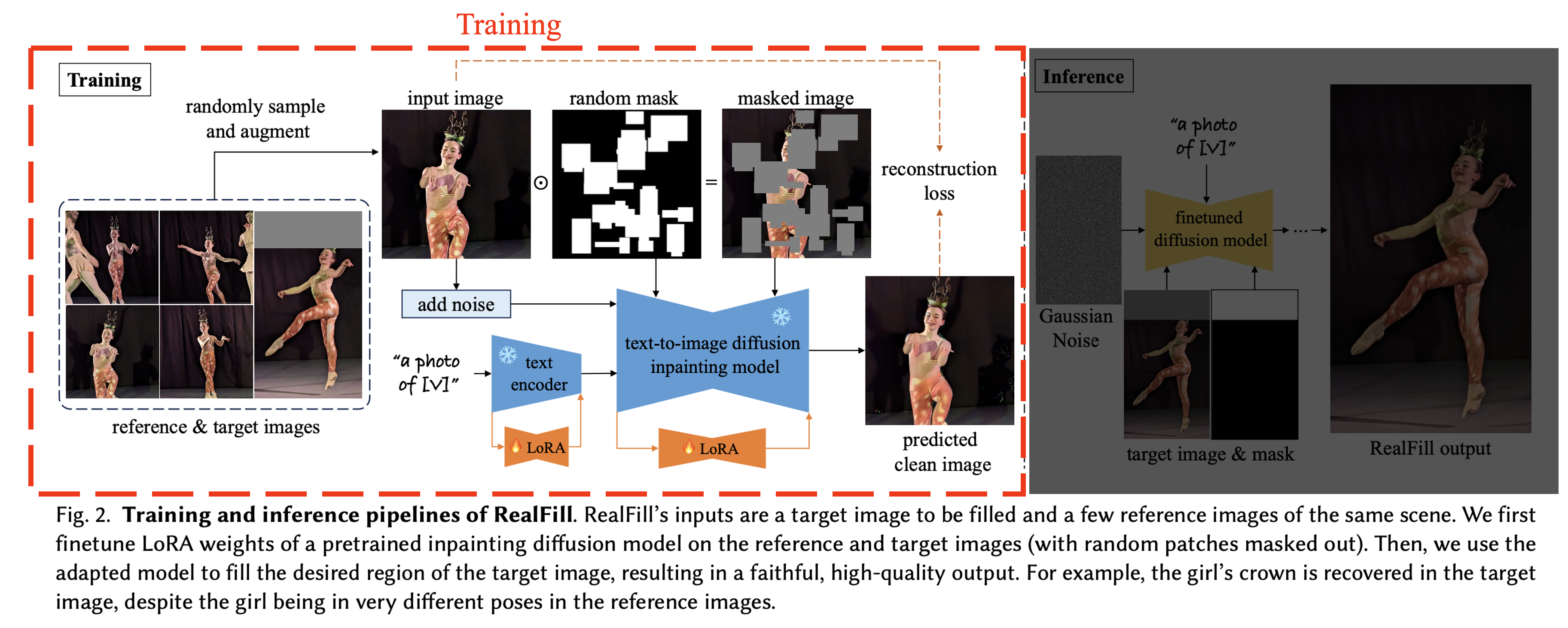
Inference. training이 끝난 후에는, DDPM sampler를 사용해 이미지를 생성\(I_{\text{gen}}\)합니다. 하지만 \(I_{\text{tgt}}\)와 \(I_{\text{gen}}\)사이 왜곡이 발생했다고 합니다. 저자들은 이를 해결하기 위해
- 먼저 마스크 \(M_{\text{tgt}}\)를 feathering(가장 자리를 부드럽게 만드는 것)
- 이를 이용해 \(I_{\text{tgt}}\)와 \(I_{\text{gen}}\)을 alpha composite 했다고 합니다.
이런 방식을 통해 저자들은 기존 영역은 보존하면서, 생성된(마스킹 되었던) 영역이 부드러운 transition을 갖도록 했습니다.

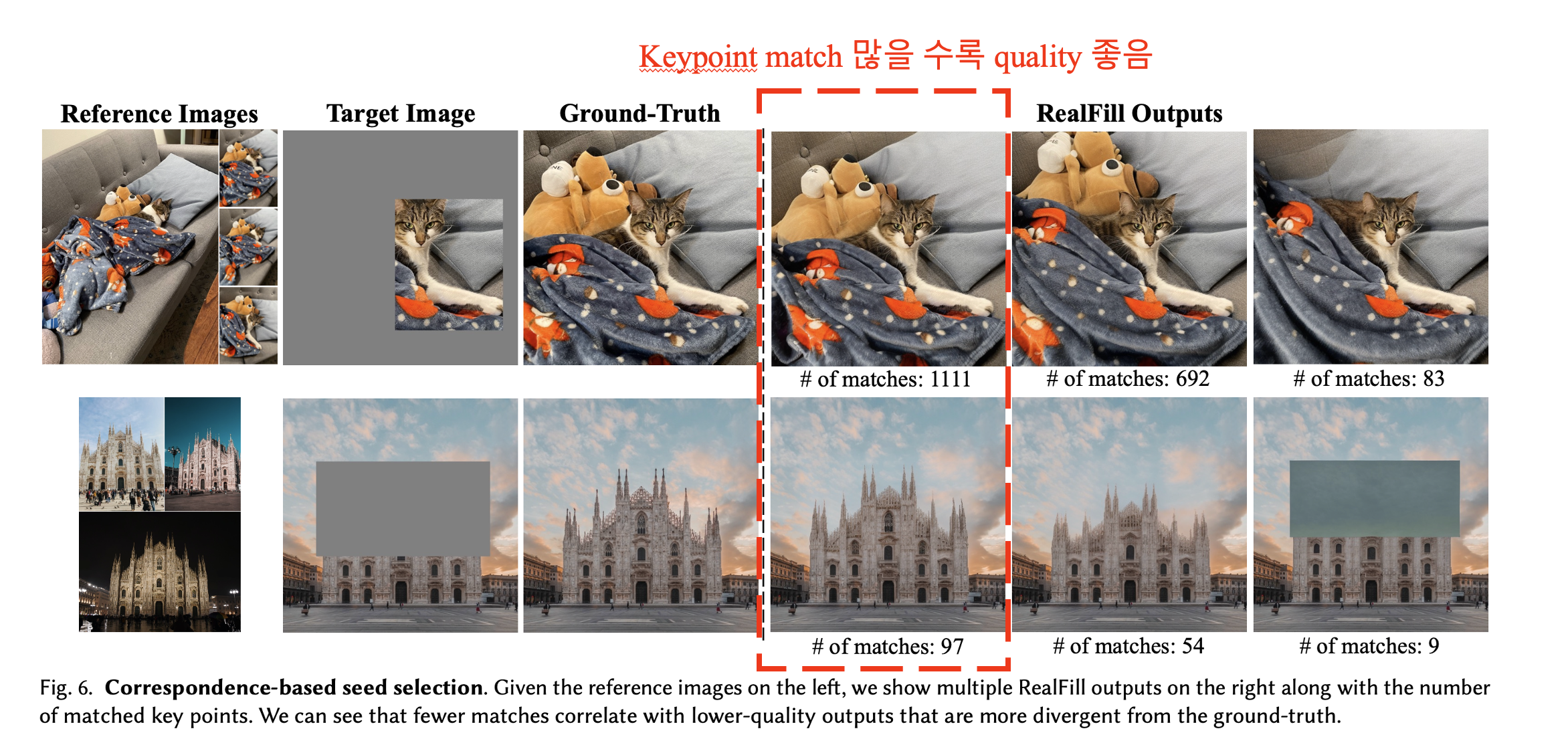
Correspondence-Based Seed Selection
Diffusion 과정은 stochastic 과정으로 random seed에따라 다른 이미지가 생성됩니다. 저자들은 Reference 이미지와 target 이미지간의 feature correspondences를 계산하여, 이 값이 높은 상위 몇 개의 결과를 자동으로 선택한다고 합니다.
4. Experiments
Qualitative Results
Inpainting, outpainting 모두에서 훌륭한 이미지 생성 능력을 보여주었는데, 저자들은 1) (pretrained model의) prior 정보와, 2) (finetuning을 통한) 장면에 대한 이해 덕분이라고 합니다.


Evaluation Dataset
기존의 참조 이미지 기반 이미지 완성 벤치마크는 주로 작은 영역을 채우고, 참조 이미지와 목표 이미지 사이의 차이를 거의 가정하지 않는 경우가 많았습니다. RealFill의 실제 사용 사례를 더 잘 평가하기 위해, 저자들은 RealBench라는 새로운 데이터셋을 생성했습니다.
RealBench는 33개의 장면(23개의 outpainting, 10개의 inpainting)으로 구성되어 있으며, 각 장면에는
- 참조 이미지 집합 \(X_{\text{ref}}\),
- 누락된 영역이 표시된 이진 마스크 \(M_{\text{tgt}}\),
- 채울 목표 이미지 \(I_{\text{tgt}}\),
- 정답 이미지 \(I_{\text{gt}}\)가 포함되어 있습니다.
각 장면의 참조 이미지 수는 1개에서 5개까지 다양합니다. 이 데이터셋은 시점, 초점 흐림, 조명, 스타일, 피사체의 자세 차이 등 다양한 조건을 포함하여 RealFill의 성능을 측정하는 데 적합하다고 합니다.
Evaluation Metrics
- Low-level: PSNR, SSIM, LPIPS (\(M_{\text{tgt}} = 1\)인 영역, 마스킹 된 영역내에서만 계산)
- Mid-level: DreamSim, 전체 이미지의 레이아웃, 객체의 자세, 의미적 콘텐츠 차이를 강조하는 지표
- High-level: DINO와 CLIP 을 통한 전체 이미지의 임베딩과, cosine distance 비교
Baseline Methods
저자들은 비교 모델을 두 그룹으로 나눕니다.
Reference image based: TransFill과 Paint-by-Example을 사용합니다. 이들은 추론 시 하나의 참조 이미지만 사용하므로, RealBench에서 각 실험마다 참조 이미지 집합 \(X_{\text{ref}}\)에서 무작위로 하나를 샘플링합니다.
Prompt-based: Stable Diffusion Inpainting과 Photoshop Generative Fill을 사용합니다. Prompt-based 모델의 성능을 극대화하기 위해, 각 장면마다 ChatGPT를 활용해 장면을 세부적으로 설명하는 맞춤형 프롬프트를 수동으로 디자인하여 높은 품질의 결과를 얻도록 했습니다.
Quantitative Comparison
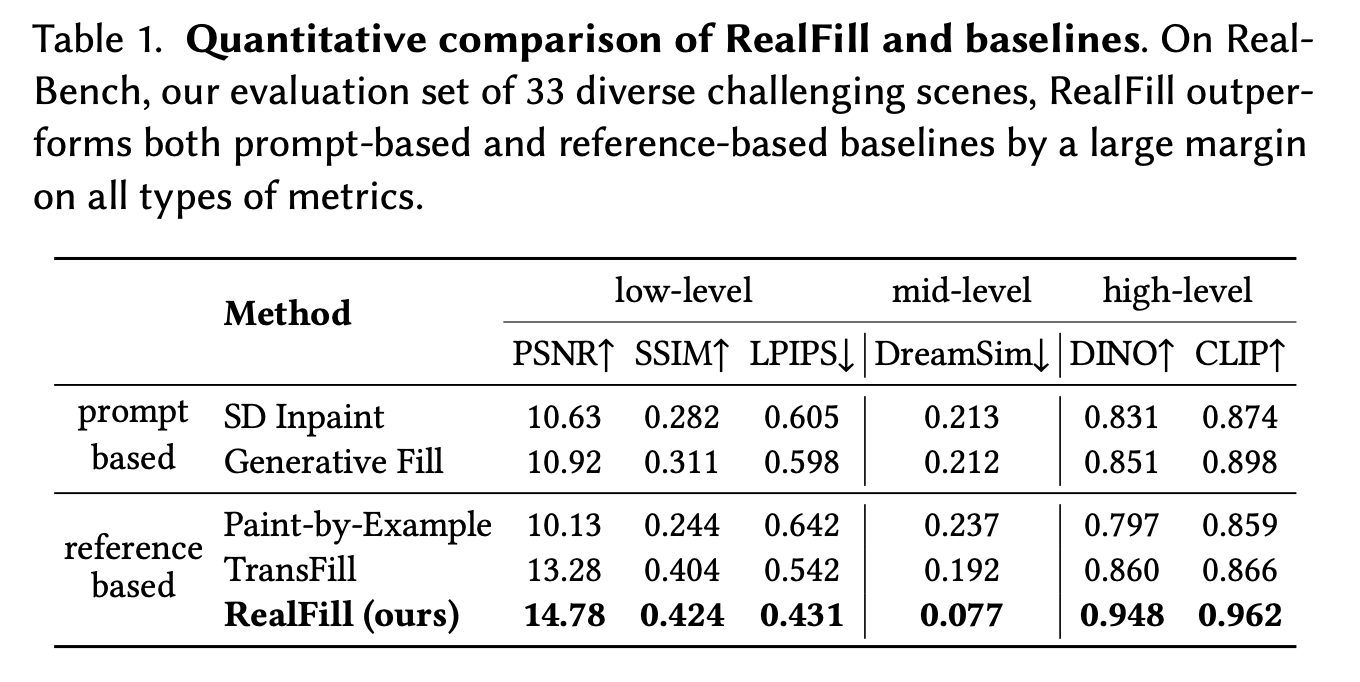
Table 1의 결과에서 RealFill이 모든 평가 지표에서 타 모델보다 크게 뛰어난 성능을 보였습니다.
Qualitative Comparison
 (흰색 마스크가 되어 있는 영역을 보고 나머지 영역을 채우는 task 결과)
(흰색 마스크가 되어 있는 영역을 보고 나머지 영역을 채우는 task 결과)
- Paint-by-Example은 참조 이미지의 CLIP 임베딩을 조건으로 사용하여 고유한 장면 구조와 물체 세부 사항을 복원하는 데 한계가 있습니다. 이는 CLIP 임베딩이 고수준의 의미적 정보만을 캡처하기 때문입니다.
- TransFill은 PSNR과 같은 낮은 수준의 평가 지표에서 양호한 성능을 보이지만, 장면이 복잡한 깊이 변화를 보일 경우 호모그래피 변환이 한계가 있어 이미지 품질이 크게 저하됩니다.
- Generative Fill은 자연 언어에 의존해 이미지를 생성하므로, 복잡한 시각적 정보를 전달하기 어려워 참조 이미지와 원본 장면 간의 차이가 나타납니다.
Correspondence-Based Seed Selection
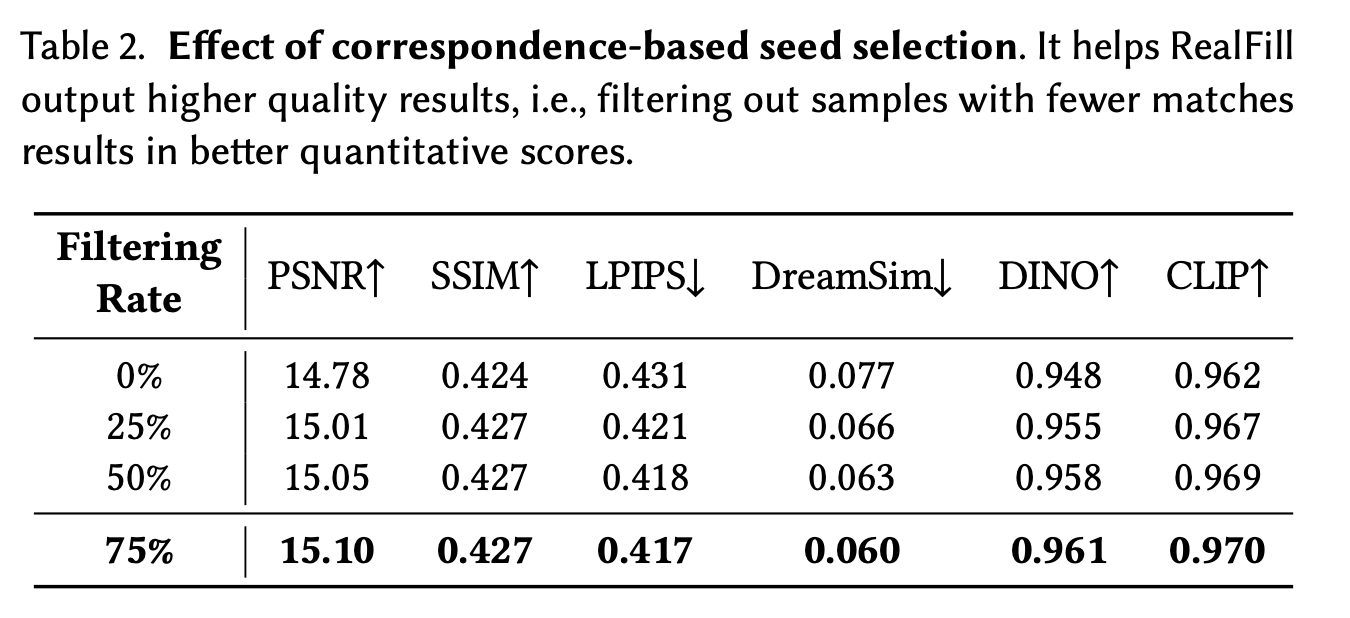
Correspondence-Based Seed Selection의 효과를 평가하기 위해, RealFill이 생성한 샘플을 일치하는 keypoint의 수에 따라 순위를 매겼고, 하위 일정 비율의 샘플을 제거했습니다. Table 2에 따르면, 상위 75%만 남겼을 때 필터링을 하지 않았을 때보다 더 나은 결과를 보였다고 합니다.
- Figure 6은 일치하는 keypoints 수와 각 결과물의 품질 간의 상관관계를 보여주며, 적은 일치 수는 일반적으로 낮은 품질을 나타냅니다.
- 각 장면마다 RealFill은 다른 노이즈 샘플을 사용해 64개의 예시를 생성하고, 이 중 keypoints 일치 기준 상위 16개만을 남긴 후 사용자에게 선택하도록 했습니다.
Discussion
How Does Reference Image Choice Affect RealFill?
참조 이미지 선택이 RealFill의 성능에 미치는 영향을 실험한 결과, 참조 이미지가 많을수록 또는 목표 이미지와의 시점 및 조명 차이가 적을수록 RealFill의 성능이 더 우수하게 나타났습니다.

Would Other Baselines Work?
- Image Stitching: 참조 이미지와 목표 이미지를 일치시켜 결합하는 이미지 스티칭 방법도 고려했습니다. 그러나 강력한 상업용 소프트웨어조차도 조명 변화나 물체의 움직임이 큰 경우에는 일치점이 부족하다고 판단하여 출력을 생성하지 못했습니다.
- DreamBooth: RealFill 대신 DreamBooth 방식으로 Stable Diffusion 모델을 참조 이미지로 미세 조정하여 사용할 수 있지만, 이 방법은 마스킹 예측 목표로 훈련되지 않기 때문에 RealFill에 비해 성능이 훨씬 떨어진다고 합니다.

What Makes RealFill Work?
Scene Composition 이해: Inference 시 조건 이미지(목표 이미지)를 빈 캔버스로 설정하여 실험해 본 결과, 모델은 장면의 다양한 구조 변형을 생성할 수 있었습니다(예: 전경 또는 배경 물체 제거, 물체 레이아웃 조정 등). 이는 RealFill이 장면 구성에 대한 이해를 갖추었음을 시사합니다.

Input Images 간의 Correspondence 캡처: 참조 이미지와 목표 이미지가 동일한 장면을 묘사하지 않더라도, 모델은 참조 이미지의 관련 내용을 목표 영역에 자연스럽게 융합해 복원을 수행합니다. Figure 12는 RealFill이 참조 이미지와 목표 이미지 간의 실제 또는 가상의 대응 관계를 캡처하여 활용할 수 있음을 보여줍니다. 이는 사전 학습된 diffusion 모델 내에서 emergent correspondence를 발견한 이전 연구들과도 유사합니다.

Limitations
속도: RealFill은 입력 이미지에 대해 Gradient-based finetuning을 요구하므로, 상대적으로 느립니다.
시점 차이에 따른 한계: 참조 이미지와 목표 이미지 사이에 시점 변화가 큰 경우, 특히 참조 이미지가 하나만 있는 경우에는 3D 장면을 정확하게 복원하지 못하는 경향이 있습니다.

- 기본 모델의 한계: RealFill은 Stable Diffusion과 같은 사전 학습된 모델의 prior에 의존하기 때문에, 기본 모델이 어려워하는 세부 묘사(예: 텍스트, 사람의 얼굴 또는 신체 부분)와 같은 경우에는 적절히 복원하지 못합니다.

6. Conclusion
이 연구에서는 Authentic Image Completion이라는 문제를 새롭게 제안했습니다. 이 문제는 참조 이미지가 몇 장 주어졌을 때, 목표 이미지에서 누락된 영역을 “있었을 것 같은 내용”으로 채우는 것을 목표로 합니다.
이를 해결하기 위해, 저자들은 RealFill이라는 간단하지만 효과적인 접근 방식을 제안했습니다. RealFill은 먼저 T2I (text-to-image) inpainting diffusion model을 참조 이미지와 목표 이미지에 대해 미세 조정한 후, 적응된 모델을 사용해 누락된 영역을 복원합니다.
실험 결과, RealFill은 시점, 조리개, 조명, 이미지 스타일, 피사체 자세와 같은 참조 이미지와 목표 이미지 간의 큰 차이에도 불구하고, 참조 이미지 내용에 충실한 고품질의 이미지 복원을 수행할 수 있음을 확인했습니다.