[Paper Reivew] An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
T2I 모델의 텍스트 임베딩 공간에서 pseudo-words를 학습하는 Textual Inversion 방법론을 제안합니다. 이를 통해 사용자는 사전 학습된 모델의 구조를 변경하지 않고 개인화된 concept을 캡처하고 새로운 장면에 삽입할 수 있습니다.

ICLR 2023 notable-top-25% [Paper], [Page]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
Tel-Aviv University, NVIDIA
2 Aug 2022
TL;DR
T2I 모델의 텍스트 임베딩 공간에서 pseudo-words를 학습하는 Textual Inversion 방법론을 제안합니다. 이를 통해 사용자는 사전 학습된 모델의 구조를 변경하지 않고 개인화된 concept을 캡처하고 새로운 장면에 삽입할 수 있습니다.
1. Introduction
Large-scale T2I는 강력한 성능을 보이지만.. 사용자가 텍스트로 원하는 것을 정확히 표현해야 한다는 제약이 존재합니다. 그렇다고 자신만의 unique concept (e.g. 자신이 키우는 고양이)을 반영하고 싶다고 re-training은 cost가 너무 많이 들고, fine-tuning을 하자니 catastrophic forgetting 문제가 발생합니다.
이에 저자들은 pre-trained 텍스트-이미지 모델의 텍스트 임베딩 공간에서 새로운 pseudo-words \(S_*\)를 학습해 새로운 개념을 표현하는 것을 목표로 합니다. 모델의 구조나 weight를 변경하지 않고도, 새로운 concept을 얻을 수 있다는 장점이 있습니다.
pseudo-words를 찾기 위해서, pre-trained T2I model에 3~5장의 reference 이미지를 가지고, “A photo of \(S_∗\)“가 reference 이미지들을 reconstruction 하도록 최적화 과정을 거칩니다. 이를 Textual Inversion 이라 합니다.
저자들의 주요 기여를 정리하자면 다음과 같습니다.
- 사용자가 제공하는 concept을 NL 기반으로 제공
- Textual Inversions 을 도입해, high-level, 디테일한 정보를 포착하는 pseudo-words 찾음.
- Embedding space를 분석해, distortion and editability trade-off
- 사용자가 text-caption을 제공한 것보다, 저자들의 방법으로 높은 품질의 이미지, robust editing 가능.
2. Related work
2.1. GAN inversion
생성 모델에서 이미지 조작을 위해서는 종종 대응하는 latent represenation을 알아야 되는데, 이 과정을 “Inversion”이라 합니다. GAN 에서는 최적화 기반, encoder 기반 방법으로 나눌 수 있습니다.
- 최적화 기반 : 잠재 벡터를 직접 최적화하여 목표 이미지를 재생성.
- encoder 기반 : 대규모 이미지 데이터를 학습하여 이미지를 잠재 표현으로 매핑.
저자들이 제안하는 접근법은 최적화 기반 방식을 따르며, unseen concept을 적용하는데 유리하다고 합니다.
2.2. Diffusion-based inversion
- Denoising process를 noised low-pass filter data를 이용해 conditioning하여 inversion을 개선
- DDIM sampling process를 closed-form으로 뒤집어서, 주어진 이미지를 생성하는 latent noise map 구함
- CLIP 기반으로 DALL-E 2에서는 이 방법을 이용해서, cross-image interpolation, semantic editing 성능 보임
이런 연구는 주어진 “image”를 latent space로 보내는 방법이지만, 저자들은 주어진 “concept”을 다룬다는 차이가 있으며, 이를 통해 직관적이고 일반화된 편집이 가능하다고 합니다.
2.3. Personalization
모델을 특정 individual, object에 개인화하려는 시도는 ML의 주요 연구 주제입니다. PALAVRA에서도 CLIP embedding space의 pseudo-words를 찾으려는 시도를 했지만, PALAVRA는 discriminative에 초점을 맞추기 때문에 새로운 장면에서 재구성하는 세부 정보를 포착하지는 못 한다고 합니다.
3. Method
저자들의 목표 : 사용자가 제공한 Concept을 guidance로 사용하는 Image generation. 이를 위해서 주어진 이미지에 대응하는 textual representation (pseudo-words)을 찾아야 함!
Latent Diffusion Models (LDM)
LDM은 크게 두 가지로 구성되어 있습니다. 각각을 살펴보자면,
- Autoencoder : 이미지를 latent space로 mapping하고, latent vector를 image로 복원
- Diffusion model : latent space에서 동작하는 diffusion model. 이때 \(c_\theta(y)\)를 conditioning vector라 하면 LDM loss는 다음과 같습니다.
Text embeddings
일반적인 Text encoder model은 text processing step으로 시작합니다. 먼저, word를 token으로 바꾸는 과정(pre-defined dictionary) 후, 각 token을 대응되는 unique embedding vector로 변환합니다. 이런 embedding vector는 일반적으로 text encoder \(c_\theta\)에서 학습 됩니다.
저자들은 이 embedding space에서 배우고 싶은 concept에 해당하는 place holder \(S_*\)로 지정하고, 학습된 embedding \(v_*\)로 기존 벡터를 대체하여, 새로운 concept을 “injecting” 하고 싶은 것입니다.
Textual Inversion
embedding \(v_*\)를 찾기 위해서, 저자들은 3~5 장의 이미를 이용해 LDM을 직접 최적화합니다.
\[v_* = \arg\min_{v} \mathbb{E}_{z \sim \mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0, 1), t} \left[ \| \epsilon - \epsilon_{\theta}(z_t, t, c_{\theta}(y)) \|_2^2 \right],\]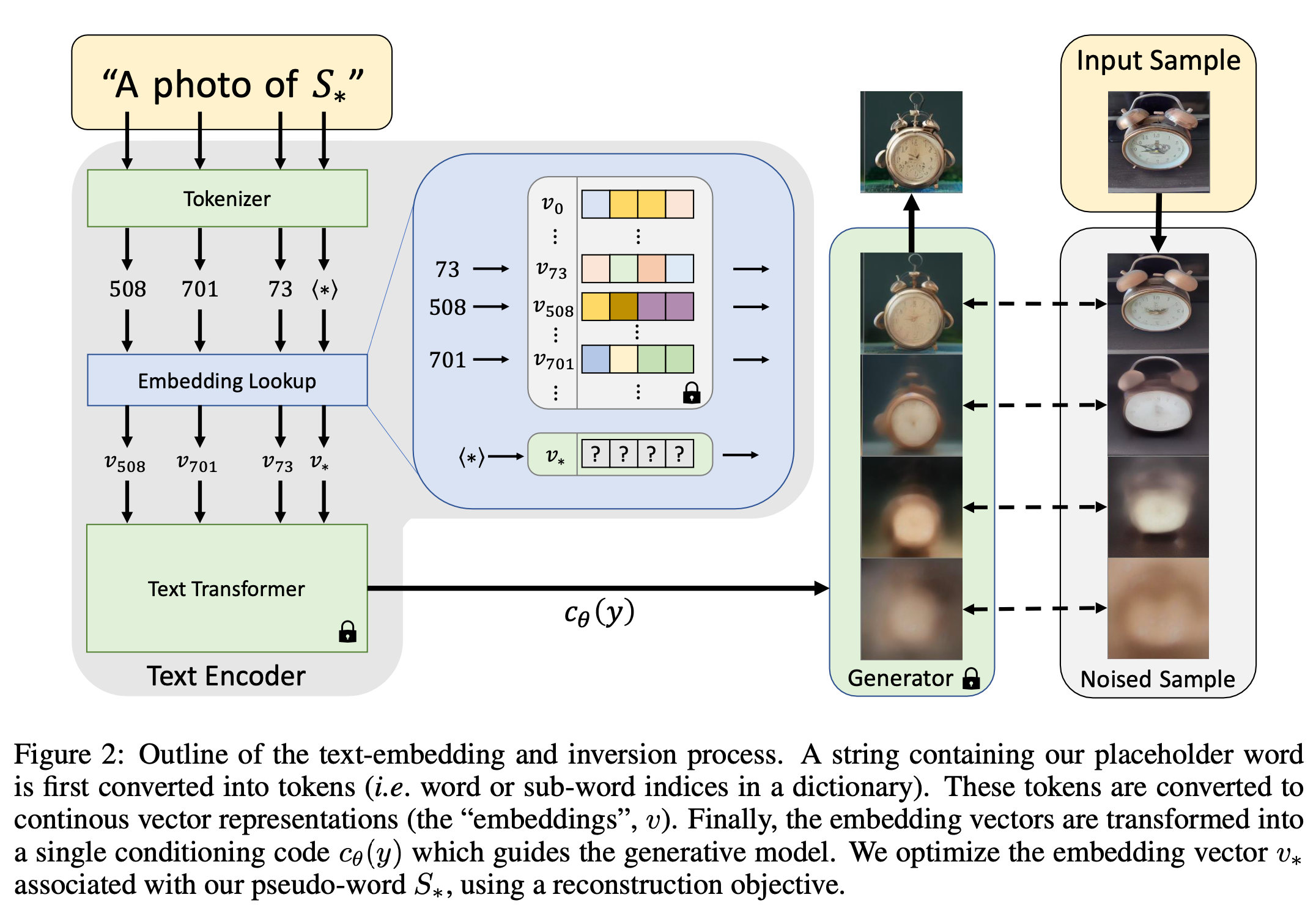
Qualitative comparisons and applications
4.1. Image variations
목표 : 1개의 pseudo-word를 사용하여 객체의 다양한 변형을 캡처하고 재구성하는 능력을 평가

DALLE-2 및 LDM보다 고유하고 개인화된 객체의 변형을 더 잘 표현하며, 생성된 이미지는 원본과 다를 수 있지만, 본질적인 특징과 세부 사항을 효과적으로 반영합니다.
4.2. Text-guided synthesis
목표 : 학습된 pseudo-words를 새로운 조건 텍스트에 통합하여 새로운 장면을 구성.

기존 방법(PALAVRA, CLIP-Guided Diffusion)의 시각적 왜곡 및 최적화 비용 문제 해결.
4.3. Style transfer
목표: 특정한, 알려지지 않은 스타일을 pseudo-words로 학습하여 새로운 이미지 생성에 적용.

단순한 객체 재구성뿐 아니라, 더 추상적인 개념(특정 스타일)을 캡처 가능.
4.4. Concept Compositions
목표: 여러 학습된 개념을 포함하는 compositional 합성을 생성.

두 개념 사이의 관계(예: 나란히 배치) 처리에 어려움. 이는 단일 개념 장면 중심으로만 훈련된 모델의 특성 때문.
4.5. Bias Reduction
문제: 텍스트-이미지 모델은 대규모 인터넷 데이터의 bias를 내재화하여 샘플 생성에 반영함. (e.g. “A CEO” → 백인 남성 이미지를 생성.)
이를 해결하기 위해, 소규모, 다양성을 반영한 데이터셋을 사용하여 새로운 “Fairer” 단어 학습.

4.6. Downstream applications
목표: 학습된 pseudo-words가 downstream에서도 활용 가능함을 입증.

Blended Latent Diffusion에서도 활용 가능.
4.7. Image curation
- 수동 큐레이션으로 결과 품질 보장.
- CLIP 기반 자동화 가능성을 제시.
5. Quantitative analysis
5.1. Evaluation Metrics
- Reconstruction: 생성된 이미지와 training set 사이 CLIP-space cosine similarity 측정
- Editability : 생성된 이미지와 text prompt 사이 cosine similarity 측정
5.2. Evaluation setups
(디테일한 내용이라 생략)
5.3. Results
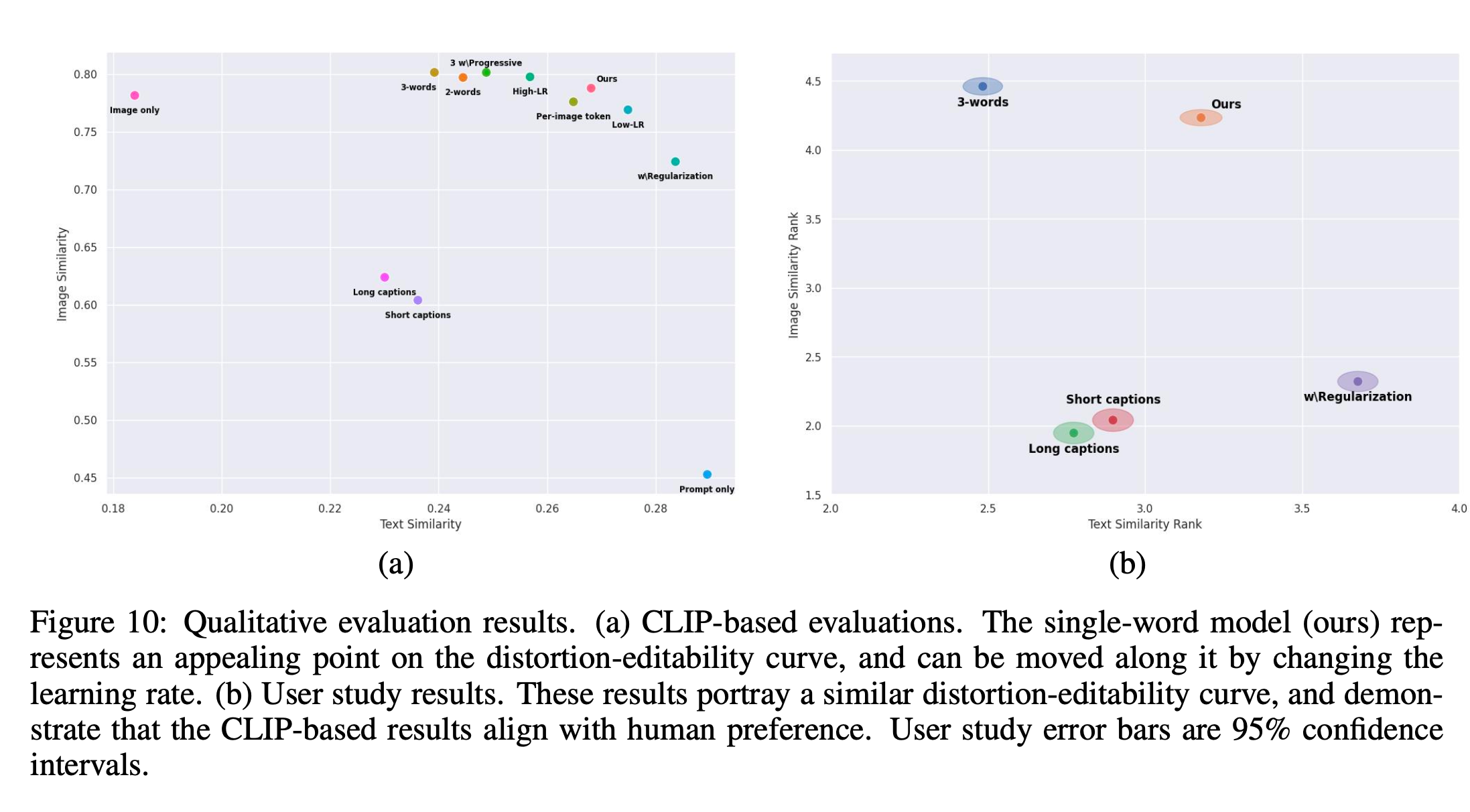
- 주요 관찰:
- 재구성 품질: 제안된 방법과 여러 비교 대상은 학습 세트의 무작위 샘플링과 비슷한 수준의 의미적 재구성 품질을 보여줌.
- 단일 단어 방법: 재구성 품질에서 다중 단어 기반 방법과 동등하며, editability은 크게 향상.
- distortion-editability trade-off:
- 임베딩 벡터가 실제 단어 분포에 가까울수록 편집이 쉬워지지만, 타겟 세부사항 재구성에는 실패.
- 벡터가 단어 분포에서 멀어질수록 재구성은 향상되지만 편집 가능성은 감소.
- 학습률 조정으로 이 트레이드오프를 제어 가능.
- 인간 설명 한계:
- 긴 캡션 사용 시 의미 있는 정보 일부만 집중하여 개념 재구성과 편집 성능이 저하.
CLIP 기반 평가의 한계:
- CLIP은 모양 보존에는 민감하지 않아 일부 결과의 평가가 부정확할 수 있음.
6. Limitations
- 정확성 부족:
- 특정 모양과 세부사항을 학습하기 어려움. 대신 개념의 “의미적 본질”을 반영.
- 최적화 시간:
- 단일 개념 학습에 약 2시간 소요.
- 직접 이미지를 텍스트 임베딩으로 매핑하는 인코더 학습으로 시간을 단축할 가능성 있음.
7. Conclusions
저자들의 주요 기여는 다음과 같습니다.
- “Textual inversion” 방법을 이용해, concept을 pseudo-word로 mapping
- 학습된 pseudo-word로 간단하게 새로운 장면에 특정 concept을 삽입할 수 있음.