[Paper Reivew] UDiffText: A Unified Framework for High-quality Text Synthesis in Arbitrary Images via Character-aware Diffusion Models
SD의 Text encoder를 저자들의 character level text encoder로 대체하고 Model의 Cross-attention block만 denoising score matching loss, local attention loss, scene text recognition loss로 fine-tune.

ECCV 2024 [Paper]
Yiming Zhao, Zhouhui Lian
Peking University
8 Dec, 2023
TL;DR
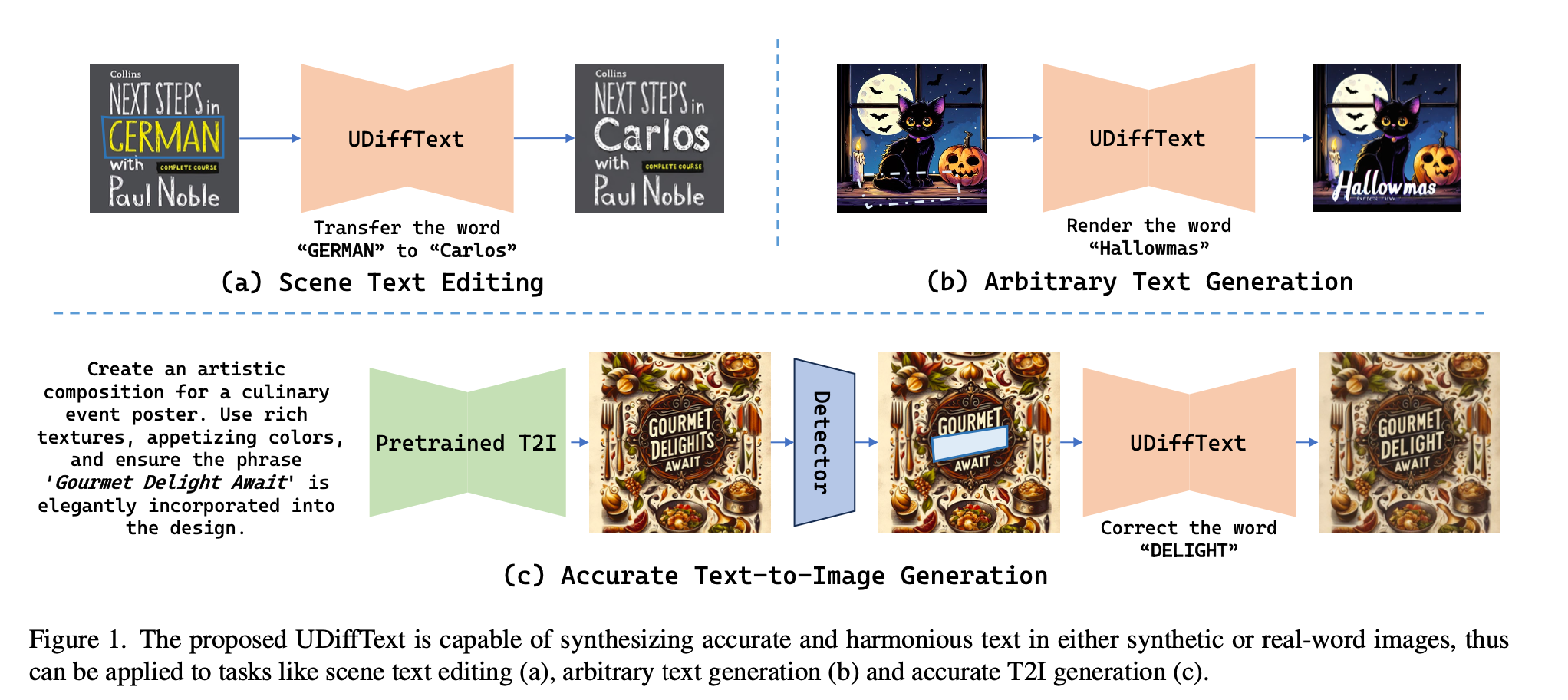
Scene Text Editing, Arbitrary Text Generation, Accurate Text-to-Image Generation 등 여러 task에 활용할 수 있는 UDiffText를 제안.
- SD의 Text encoder를 저자들의 character level text encoder로 대체하고,
- Model의 Cross-attention block만 denoising score matching loss, local attention loss, scene text recognition loss로 fine-tune.
- Inference stage에서 Refinement of Noised Latent로 추가적인 성능 향상.
1. Introduction
Diffusion 기반 T2I model의 성능이 매우 발전되고 있기는 하지만… Text rendering은 아직 challenging한 문제라고 합니다.

- Character-Aware Models Improve Visual Text Rendering 논문의 저자들은 Text encoder의 부적절한 information으로 인해 text rendering issue가 발생한다고 합니다. (Character-Aware text encoder가 이 문제를 어느정도 완화)
- DALL-E3의 저자들도 “~~~~” 같은 text prompt가 들어오면 이미지를 제대로 생성하지 못하는 문제를 확인했다고 합니다. Text encoder (T5)에서 전체 단어를 완전히 이해하고 image에 mapping해줘야 하는데, 이 과정에서 필연적으로 불안정한 text rendering으로 이어진다고 합니다.
본 논문의 저자들은 이런 spelling issue의 원인을 T2I model의 근본적인 문제와 연관되어 있다고 하며 catastrophic neglect, incorrect attribute binding 라는 문제로 정의합니다.
이 문제를 다루기 위해 저자들은 character-level text encoder를 학습시켜 T2I 모델의 Text encoder를 대체하고 (more robust), 이후 model의 작은 부분만 score matching, (proposed) local attention map constraint를 이용해 fine-tune 하는 UDiffText를 제안합니다. 추가적으로 Inference 단계에서 refinement process를 거쳐 더 정확한 text rendering을 가능하게 했다고 합니다.
저자들의 주요 contribution은 다음과 같습니다.
- SD의 Text encoder를 저자들의 character level text encoder로 대체하고,
- Model의 Cross-attention block만 denoising score matching loss, local attention loss, scene text recognition loss로 fine-tune.
- Inference stage에서 Refinement of Noised Latent로 추가적인 성능 향상.
- Scene Text Editing, Arbitrary Text Generation, Accurate Text-to-Image Generation 등 여러 task에 활용 가능.
2. Related Work
2.1. Guided Diffusion
CFG이후 diffusion model의 controllability를 향상시키려는 연구가 많이 존재했습니다.
- Image condition을 noise에 concat. (InstructPix2Pix, Glide, Palette)
- Prompt tuning (Textual Inversion, CustomDiffusion)
- Construct bypass network (T2I-adapter, ControlNet)
또한 Cross-Attention(CA) mechanism은 생성과정의 pivotal입니다.
- Prompt-to-prompt : CA map이 생성된 이미지의 공간적 Layout에 큰 영향을 준다는 것을 확인
- Perfusion : CA map의 Key는 region, Values는 그 region의 feature에 영향을 줌.
- Structed Diffusion: Noun phrase extraction을 통해 더 정확한 CA feature 얻고 semantic attribute leakage 완화.
- FastComposer : CA map과 subject segmentation mask를 align 시켜서 multi subject generation에서 identity blending 문제 완화.
- Attend-and-excite: Diffusion model이 모든 subject token에 attend 할 수 있도록 CA Unit을 refine.
(본 논문에서는 Character-level segmentation map guidance를 이용해 CA map에 constraint을 걸어주어 text rendering 성능을 향상시켰다고 합니다.)
2.2. Scene Text Generation
GAN 기반 방법으로는
- STEFANN : Edit single character, implement placement algorithm.
- SRNET, MOSTEL : text generation task를 1) background inpainting, 2) text-style transfer로 divide.
Diffusion 기반 방법으로는
- DiffSTE : Dual encoder 구조 사용 (Character text encoder + instruction text encoder), Instruction tuning.
- DiffUTE : OCR-based glyph encoder 사용해 glyph guidance 사용.
- GlyphControl : ControlNet 사용해 reference 이미지를 postion & glyph guidance로 사용.
- TextDiffuser : Segmentation mask를 conditional input처럼 concat, character aware loss 사용.
본 논문에서 저자들은 SD의 Text encoder(CLIP)을 저자들의 character-level text encoder로 대체하였다고 합니다.
- Pre-trained Scene Text Recognition(STR) model을 이용해 contrastive learning.
- CA block을 fine-tune해 efficient Key, Value 값 얻기.
3. Method
저자들의 Framework는 SD v2의 inpainting variant를 backbone으로 구현되었다고 합니다.
먼저 간단하게 보자면
- SD의 Text encoder를 저자들의 character level text encoder로 대체하고,
- model의 Cross-attention block만 denoising score matching loss, local attention loss, scene text recognition loss로 fine-tune.
- Inference stage에서 Refinement of Noised Latent로 추가적인 성능 향상.
하나씩 살펴 봅시다.
3.1. Character-level Text Encoder
Recall ! Character-Aware Models Improve Visual Text Rendering 논문의 저자들은 Text encoder의 부적절한 information으로 인해 text rendering issue가 발생한다고 합니다. (Character-Aware text encoder가 이 문제를 어느정도 완화)
저자들은 character level에서 동작하는 CLIP-like text encoder를 다음과 같이 구현했다고 합니다.
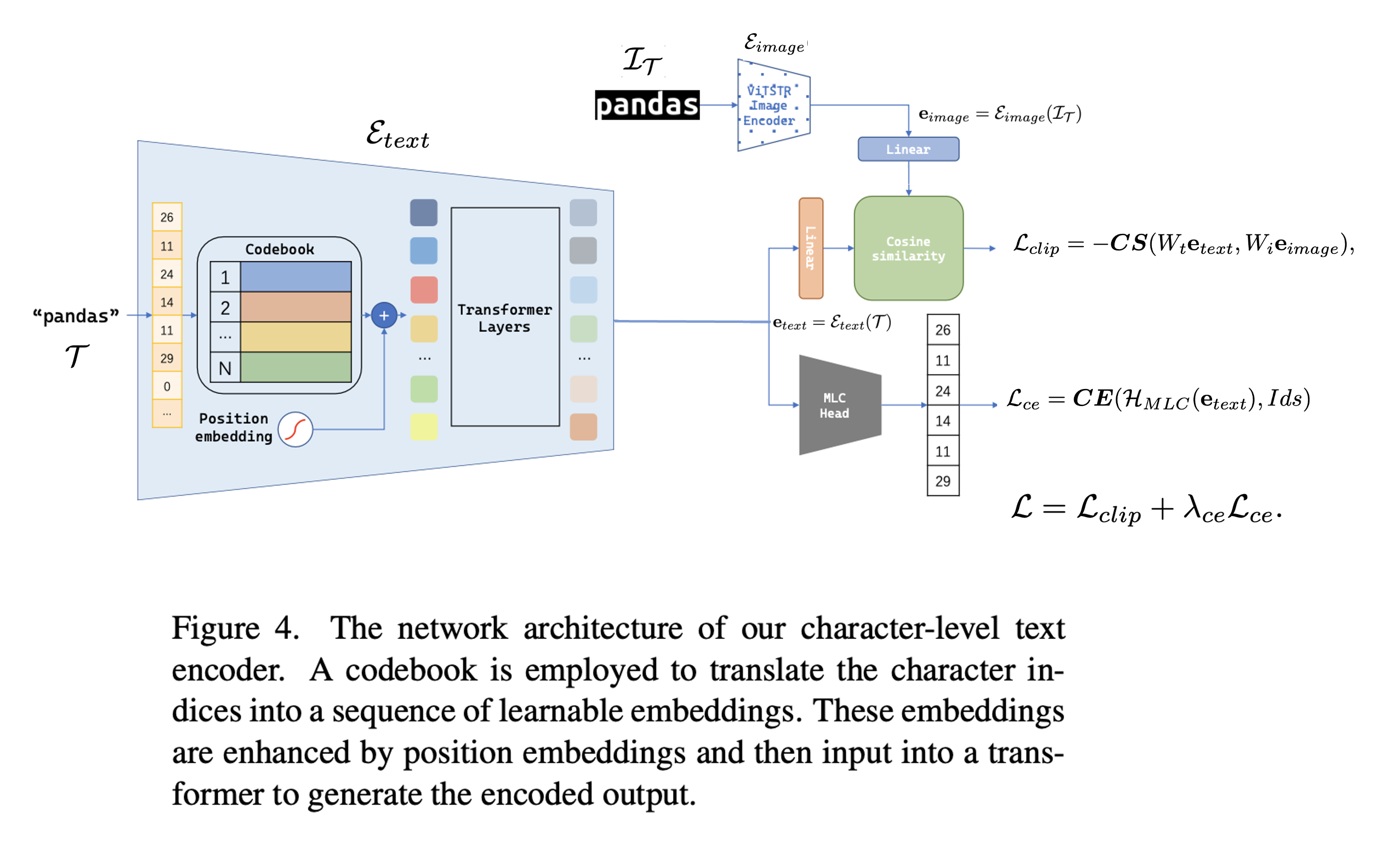
Text와 text-image 사이 embedding을 cosine similarity로 측정(CLIP loss)하고, text embedding을 multi- label classification head \(\mathcal{H}_\text{MLC}\)에 태워 Cross entropy loss도 함께 사용합니다.
(저자들은 \(\lambda_{ce} = 0.1\) 사용)
3.2. Training Strategy
Character-level Text Encoder를 학습한 다음에는 Inpainting diffusion model의 Cross Attention layer를 fine-tune 합니다.
Input으로 1) noise한 이미지, 2) mask, 3) masked clean image 세 개가 들어갑니다. 이때 U-Net의 CA layer 파라미터 값만 fine-tune하는데, loss는 3가지를 활용합니다.
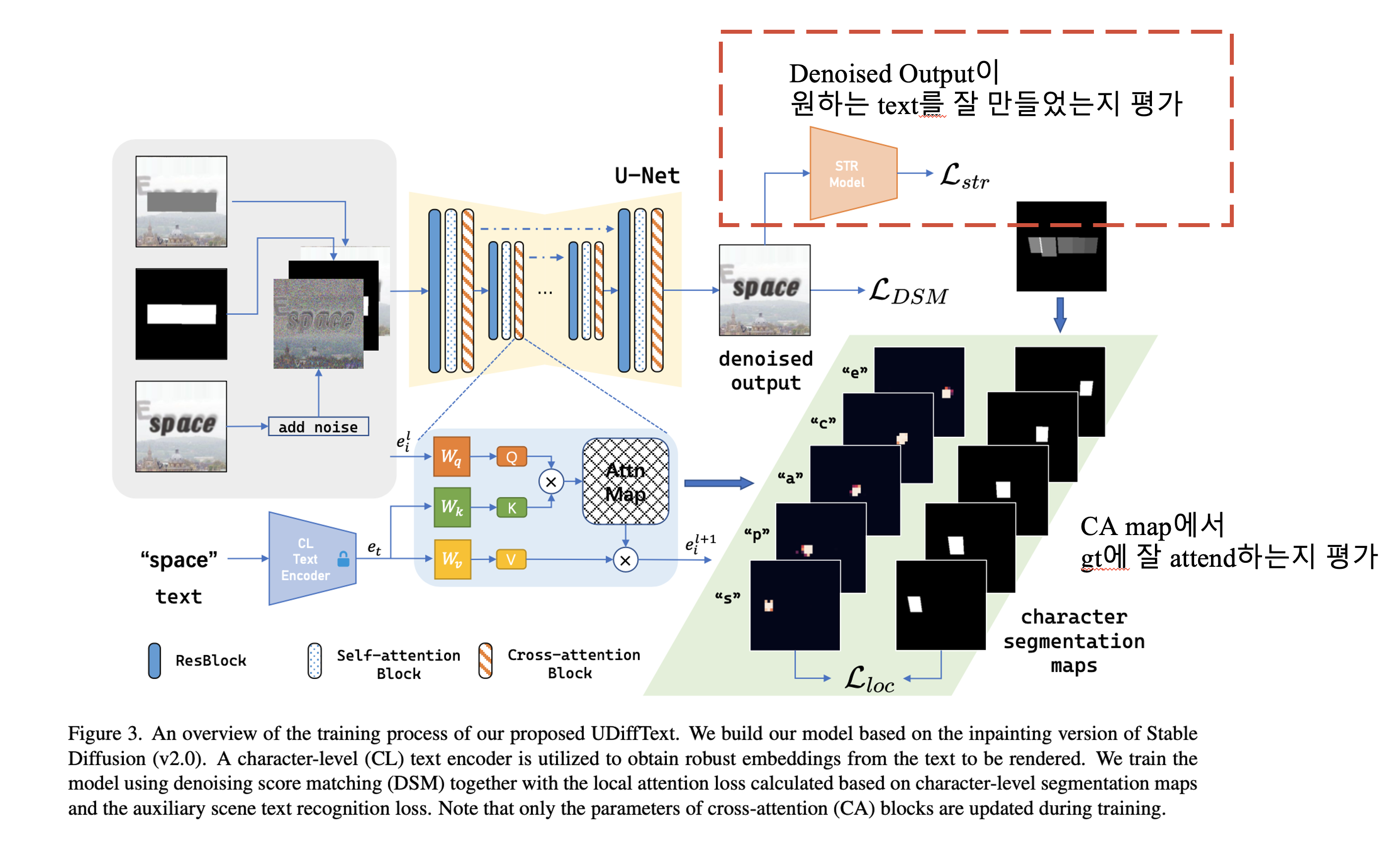
- Denoising score matching (DSM) loss : \(\mathcal{L}_{DSM} = \lambda_{\sigma} \left\| D_{\theta}(\mathbf{x}_0 + \mathbf{n}; \sigma, \mathcal{T}, \mathcal{M}, \mathbf{x}_{\mathcal{M}}) - \mathbf{x}_0 \right\|_2^2\)
기본적인 Diffusion loss라고 생각하면 됩니다. 이때 weighting은 \(\lambda_{\sigma} = \sigma^{-2}\)를 사용했다고 합니다.
- Local attention loss : 각 character에 CA block이 잘 attend 하도록 걸어주는 loss입니다. CA map과 character segmentation map 사이 loss를 계산합니다.
- Scene text recognition (STR) loss : Text rendering 정확도를 높이기위해 pre-trained STR model (Scene text recognition with permuted autoregressive sequence models.)을 사용해, Output image의 mask 부분을 STR 모델에 태워 원하는 text 가 잘 생성되었는지 비교하는 STR loss를 추가했다고 합니다.
최종 loss는 다음과 같습니다.
\[\mathcal{L} = \mathcal{L}_{DSM} + \lambda_{loc} \mathcal{L}_{loc} + \lambda_{str} \mathcal{L}_{str}.\](저자들은 \(\lambda_{loc} = 0.01\), \(\lambda_{str} = 0.001\) 사용)
3.3. Refinement of Noised Latent
Chracter-level text encoder (sec 3.1)과 model fine-tuning (sec 3.2)를 했음에도 여전히 일부 철자를 빼버리는 spelling error가 발생했다고 합니다. 이를 저자들은 catastrophic forgetting이라고 합니다.
이를 해결하기 위해 Inference stage에서 noised latent를 refine하는 과정을 도입했다고 합니다. Attend-and-excite 에서 영감을 받아, Attention이 각 character에 잘 걸리도록 다음의 loss를 정의합니다.
\[\mathcal{L}_{aae}(\mathcal{A}, \mathcal{M}) = -\frac{1}{C} \sum_{i=1}^{C} \left\{ \min_{1 \leq j \leq N} \left( \max \left( \mathbb{G} \left( \mathcal{A}_i^j \right) \odot \mathcal{M} \right) \right) \right\}.\]저자들의 Refinement of Noised Latent는 2 step으로 진행됩니다.
Optimal initial noise 찾기 Noise를 \(N\)번 샘플링, (저자들은 2 step) denoising step을 거친 뒤 \(\mathcal{L}_{aae}\)가 가장 작은 Optimal noise를 택합니다.
Inference할 때 noise latent refine : Optimal noise를 이용해 inference르 진행하면서 noise latent에 추가적인 optimization 과정을 추가합니다.
전체적인 Algorithm은 다음과 같습니다.

4. Experiments
4.1. Datasets and Evaluation Metrics
- Training Datasets:
- SynthText in the Wild: 자연 장면 기반 합성 데이터셋, 문자 수준 segmentation 맵 생성 가능.
- LAION-OCR: 광고, 메모 등 다양한 텍스트 이미지를 포함한 대규모 데이터셋.
- Validation Datasets:
- ICDAR13: 수평 텍스트 감지 평가.
- TextSeg: 세분화 중심의 실제 텍스트 이미지.
- LAION-OCR: 훈련에 사용되지 않은 데이터 사용.
4.2. Quantitative and Qualitative Results
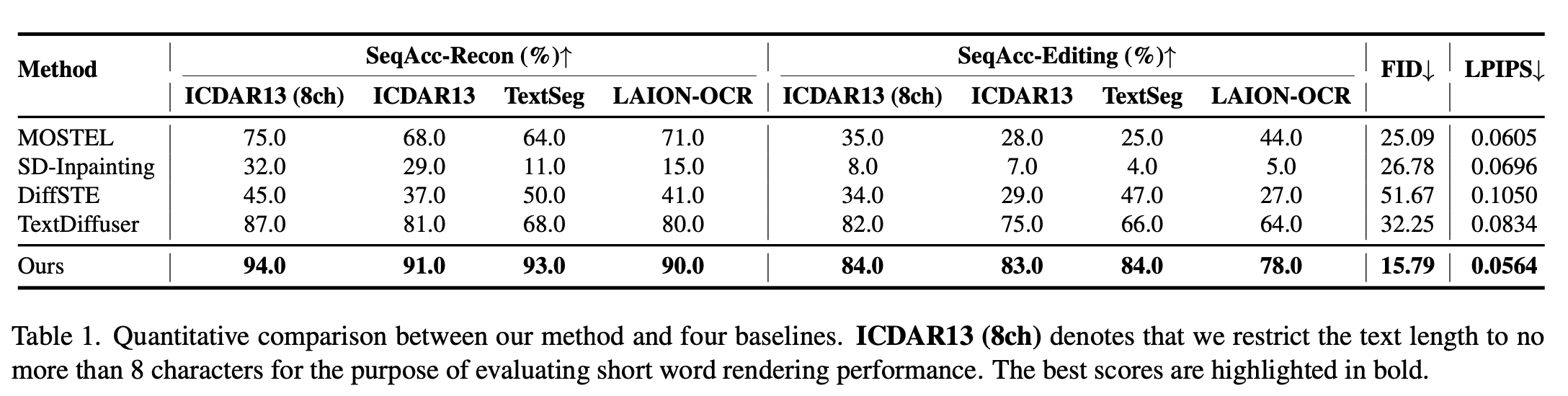
Recon, editing 모두에서 가장 좋은 성능을 기록했습니다.

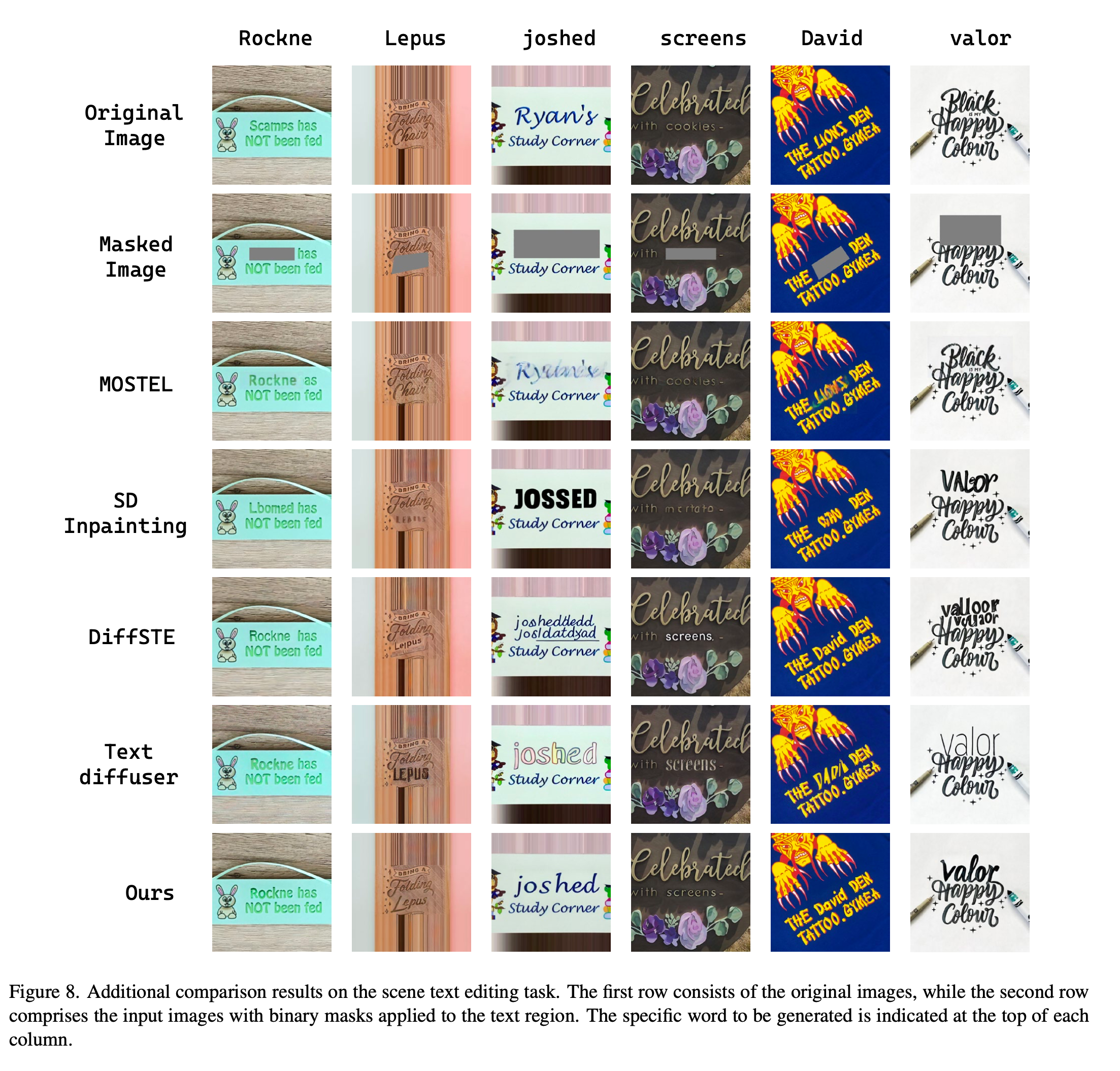

원형 글씨도 어느정도 잘 쓰는 것을 확인할 수 있습니다.
4.3. Ablation Study
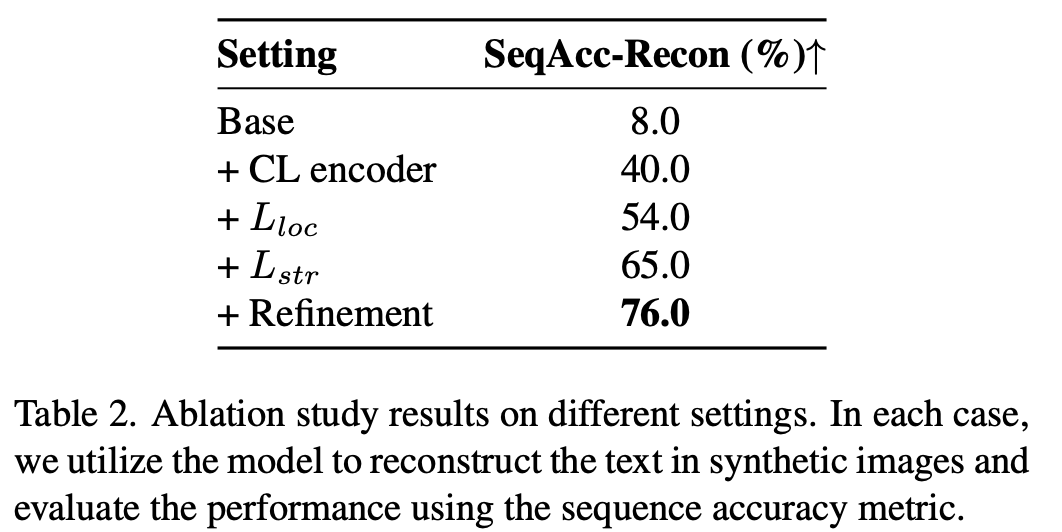
ablation study를 통해 저자들의 디자인을 검증했습니다.
또한 일반적인 SD 모델을 사용한 CA map과 저자들의 CA map을 분석한 결과, character 위치에 attention이 잘 걸리는 것을 확인할 수 있습니다.

4.4. Applications
저자들의 UDiffText는 다양한 task에 적용할 수 있다고 합니다.
5. Limitations
- 시각적 맥락에 의존 → 단순 배경에서는 일관된 텍스트 생성이 어려움.
- 최대 12자까지의 텍스트 시퀀스만 만족스러운 성능 제공.
- 긴 텍스트를 처리하려면 단어 단위 합성 방법이 필요.