
[Paper Reivew] Vector Quantized Diffusion Model for Text-to-Image Synthesis (VQ-Diffusion)
VQ-VAE의 latent space를 diffusion model을 이용해 모델링하여, 기존 AR 방식 모델들이 갖는 문제점을 해결한 연구입니다.
VQ-VAE의 latent space를 diffusion model을 이용해 모델링하여, 기존 AR 방식 모델들이 갖는 문제점을 해결한 연구입니다.

사전학습된 CLIP과 DDPM을 이용하여, 배경을 보존하면서 마스킹 부분을 text-prompt에 맞게 이미지를 생성하는 방법론을 제시한 논문입니다.

새로운 Self-supervised learning framework을 제시해 기존 convnet을 능가하는 ViT성능을 보인 연구입니다.

기존 확률적 모델링 방법을 Stochastic Differential Equation(SDE)로 일반화하면서, 새로운 방식의 프레임워크를 제시한 논문입니다.

T2I Diffusion의 personalization의 방법론 논문의 리뷰입니다.

Classifier 없이 Classifier Guidance를 하는 방법론을 제시하며, 이미지 품질과 다양성을 trade-off 할 수있음을 보인 논문입니다.

Diffusion model로 GAN의 성능을 넘어선 ADM에 대한 리뷰입니다.
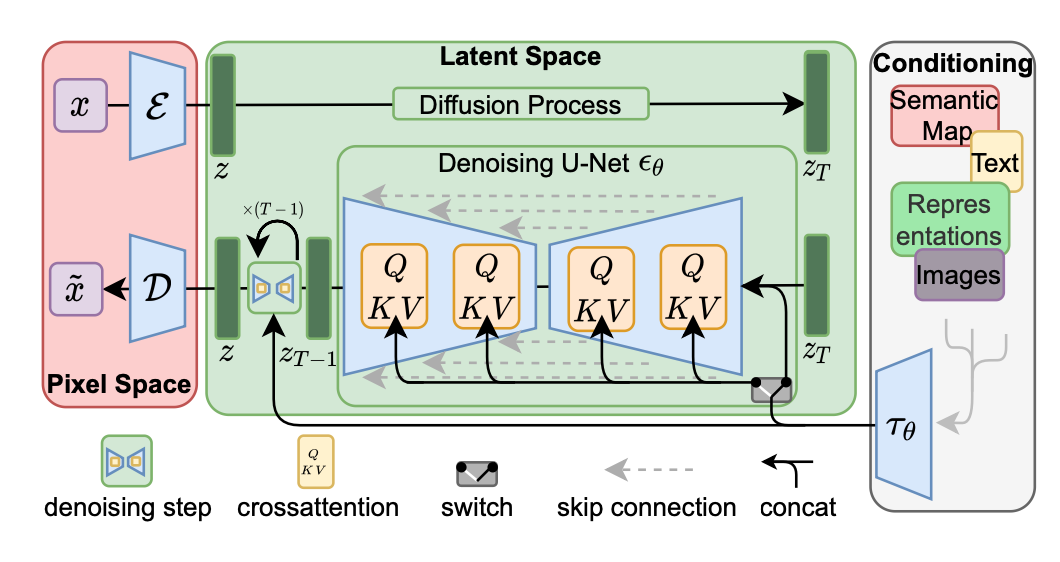
LDM paper를 읽고 요약한 내용입니다.

Diffusion model의 간단한 이해를 돕기위한 포스트입니다.
Jekyll Chripy template을 사용해 포스팅하는 튜토리얼입니다.